Welcome to shock's blog
一路走来,且行且珍惜。-
快速通过ELK实现日志统一收集展示
场景说明
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。 一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。 Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。 Filebeat隶属于Beats。目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
本文所试验的场景如下,其中日志收集采用Filebeat:

环境准备
提前准备kafka环境,下载es、kibana、logstash、filebeat等软件,版本号为5.6.10,使用可以直接运行包解压即可运行。 本文为简化起见,只在单机上安装,通过elk用户安装,预先安装Jdk8。

Filebeat配置启动
提前准备kafka主题messages,配置读取/var/log/messags数据到kafka主题。 解压Filebeat介质,进入软件目录,修改配置vim filebeat.yml

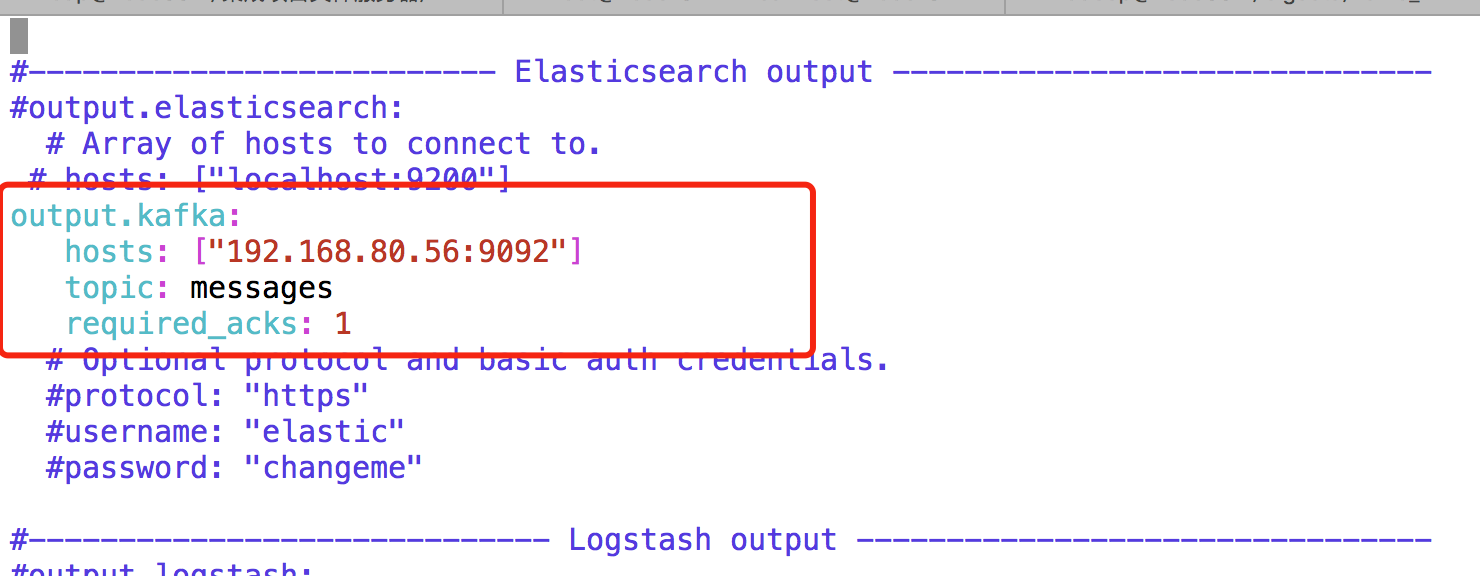 输入命令,nohup ./filebeat -e -c filebeat.yml>/dev/null 2>/dev/null & ,启动fliebeat
Kafka主题中会接收到对应消息。
输入命令,nohup ./filebeat -e -c filebeat.yml>/dev/null 2>/dev/null & ,启动fliebeat
Kafka主题中会接收到对应消息。Logstash与ES配置启动,将kafka消息采集到ES中
解压ES软件,修改config/elasticsearch.yml配置文件,具体配置如下。
cluster.name : es_cluster node.name : node0 path.data: /home/elk/es/data path.logs: /home/elk/es/logs network.host : node68 http.port : 9200 http.cors.enabled: true http.cors.allow-origin: "*"直接启动可能会报错,需要通过root用户修改max file和max_map_count。 [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
启动ES,通过浏览器访问,说明启动正常。
[elk@node68 elasticsearch-5.6.10]$ bin/elasticsearch -d [elk@node68 elasticsearch-5.6.10]$ ps -ef |grep elas elk 14511 1 99 10:56 pts/0 00:00:13 /home/elk/jdk8/bin/java -Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -Djdk.io.permissionsUseCanonicalPath=true -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Dlog4j.skipJansi=true -XX:+HeapDumpOnOutOfMemoryError -Des.path.home=/home/elk/elasticsearch-5.6.10 -cp /home/elk/elasticsearch-5.6.10/lib/* org.elasticsearch.bootstrap.Elasticsearch -d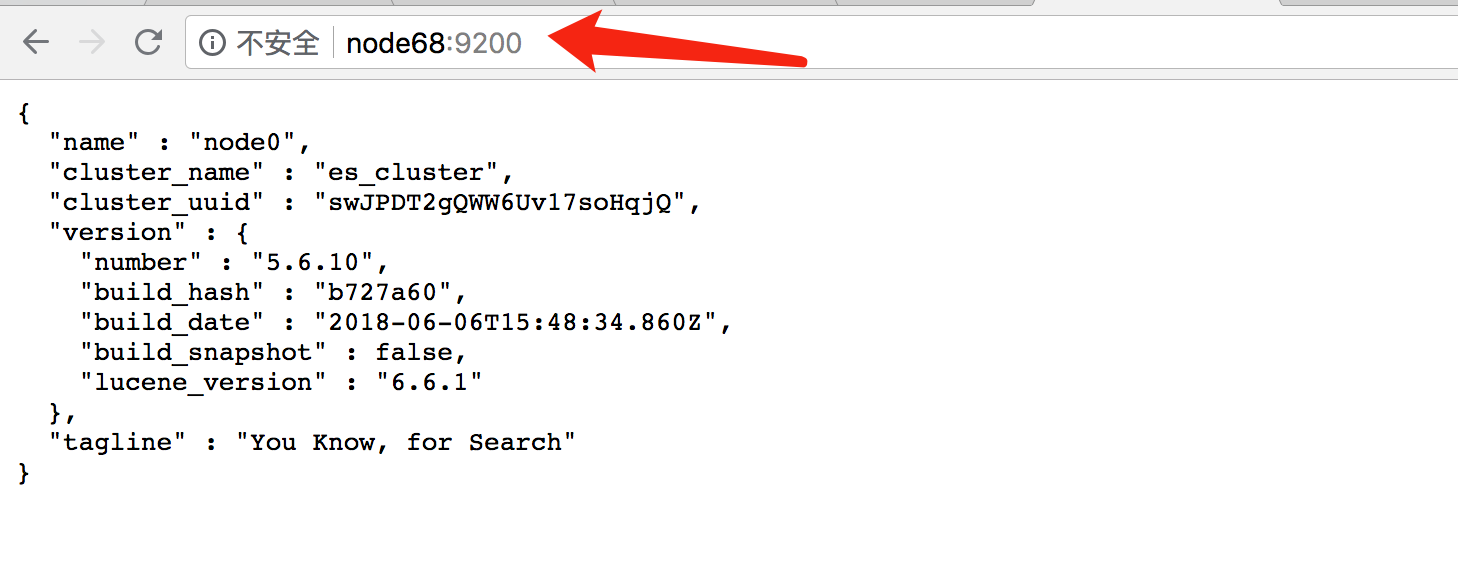 解压Logstash,新建kafka2es.yml配置文件,将kafka主题消息采集到ES中。配置文件内容如下
解压Logstash,新建kafka2es.yml配置文件,将kafka主题消息采集到ES中。配置文件内容如下input{ kafka { bootstrap_servers => "192.168.80.56:9092" topics => ["messages"] group_id => "consumer-zwang" auto_offset_reset => "earliest" } } output { elasticsearch { hosts => "node68:9200" codec => json } }在安装目录下输入命令,启动logstash。
[elk@node68 logstash-5.6.10]$ bin/logstash -f kafka2es.yml --config.reload.automatic & [1] 19501启动Kibana,实现展示ES数据
解压kibana,进入安装目录,修改config/kibana.yml文件,配置ES地址和本机地址。
 输入命令启动Kibana
输入命令启动Kibana[elk@node68 kibana-5.6.10-linux-x86_64]$ bin/kibana & [2] 19662打开浏览器,输入Kibana地址,默认端口是5601,可以搜索到messages日志信息

总结
增加Kafka的目的是由于Logstash在数据量大的时候会非常消耗资源,通过Kafka可以实现数据缓冲的作用。另外本文中没有对日志进行过滤处理,Logstash擅长对日志进行清洗加工,以满足日志分析需求,配置文件中通过filter脚本实现数据的清洗加工。本文中的kafka、ES、Logstash原则上都是分布式集群环境,以实现高性能高可用。
Flume也是实现实时数据采集的工具,与Logstash相比,Flume侧重数据的传输可靠性,Logstash则更轻量级,易于与其他组件配合使用,场景广泛。
Logstash支持数据输出到Hadoop环境,支持通过Socket端口收集数据,支持数据写入Redis等场,对MySQL、HBase输出连接需要定制组件才能完成数据传输。
资源
- 官网地址:https://www.elastic.co/
- 中文社区:https://elasticsearch.cn/
-
Hadoop平台中的透明数据加密
什么是透明数据加密
TransparentData Encryption用来加密数据文件里的数据,保护从底层对数据的安全访问。所谓透明是指对使用者来说是未知的,当使用者在写入数据时,系统会自动加密,当使用数据时系统会自动解密。Oracle、SQLServer很早就支持了透明数据加密的特性,下面说一下针对HDFS文件和HBase的透明数据加密过程。
HDFS KMS透明加密配置及测试
HDFS Encryption zone加密空间是一种end-to-end(端到端)的加密模式.其中的加/解密过程对于客户端来说是完全透明的.数据在客户端读操作的时候被解密,当数据被客户端写的时候被加密,所以HDFS本身并不是一个主要的参与者,形象的说,在HDFS中,你看到的只是一堆加密的数据流.
Encryption zone原理介绍
- 每个encryption zone 会与每个encryption zone key相关联,而这个key就是会在创建encryption zone的时候同时被指定。
- 每个encryption zone中的文件会有其唯一的data encryption key数据加密key,简称就是DEK。
- DEK不会被HDFS直接处理,取而代之的是,HDFS只处理经过加密的DEK, 就是encrypted data encryption key,缩写就是EDEK。
- 客户端询问KMS服务去解密EDEK,然后利用解密后得到的DEK去读/写数据。
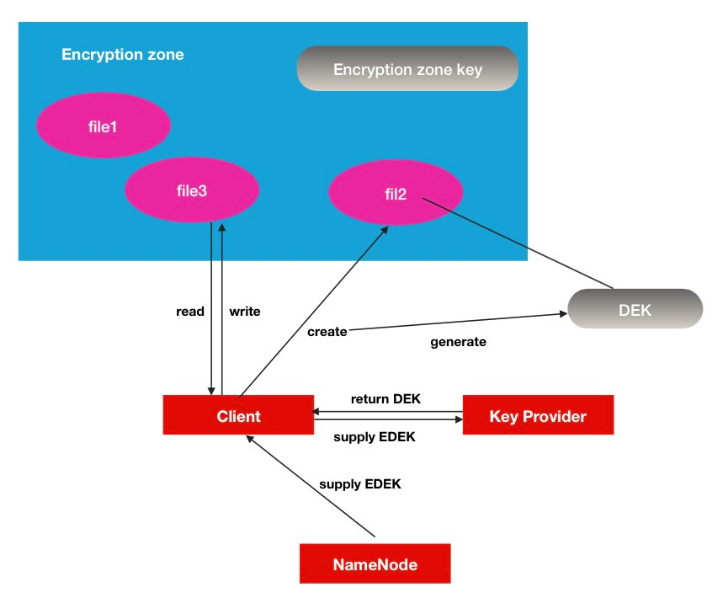 Key Provider可以理解为是一个key store的保存库,其中KMS是其中的一个实现。
Key Provider可以理解为是一个key store的保存库,其中KMS是其中的一个实现。
环境准备
本文中的大数据环境通过CloudManager5.12进行安装,Hadoop版本为hadoop 2.6.0-cdh5.12.1。 通过CM直接安装Java KeyStore KMS服务。 按照默认选项可完成安装,KMS服务使用Kerberos进行认证。
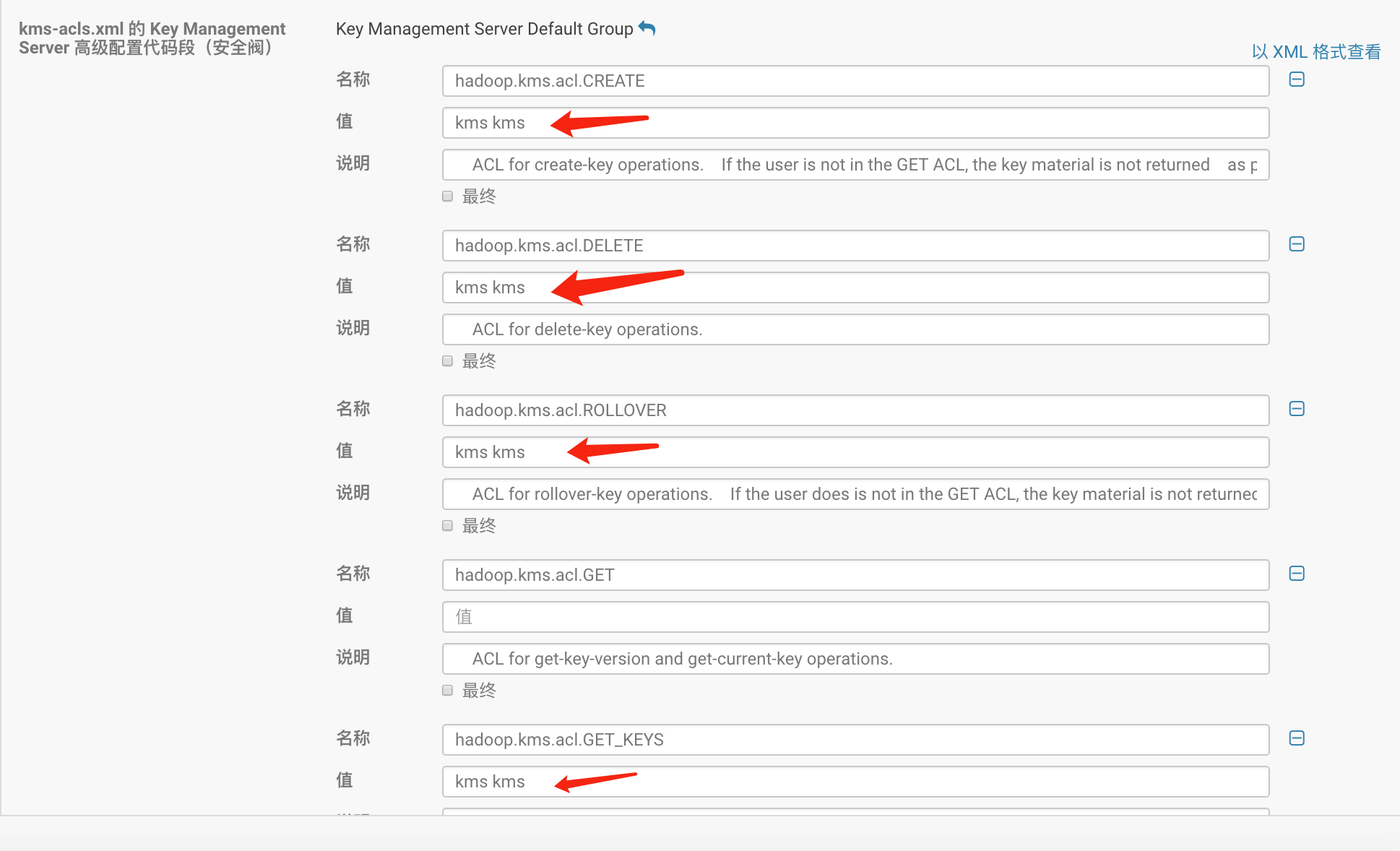
 管理员用户名设置为kms,组名设置为kms,此用户可以管理所有KMS密钥。
管理员用户名设置为kms,组名设置为kms,此用户可以管理所有KMS密钥。
 安装KMS后,CM自动KMS服务作用于Hadoop,相关引用KMS服务的组件均需要重启。
安装KMS后,CM自动KMS服务作用于Hadoop,相关引用KMS服务的组件均需要重启。
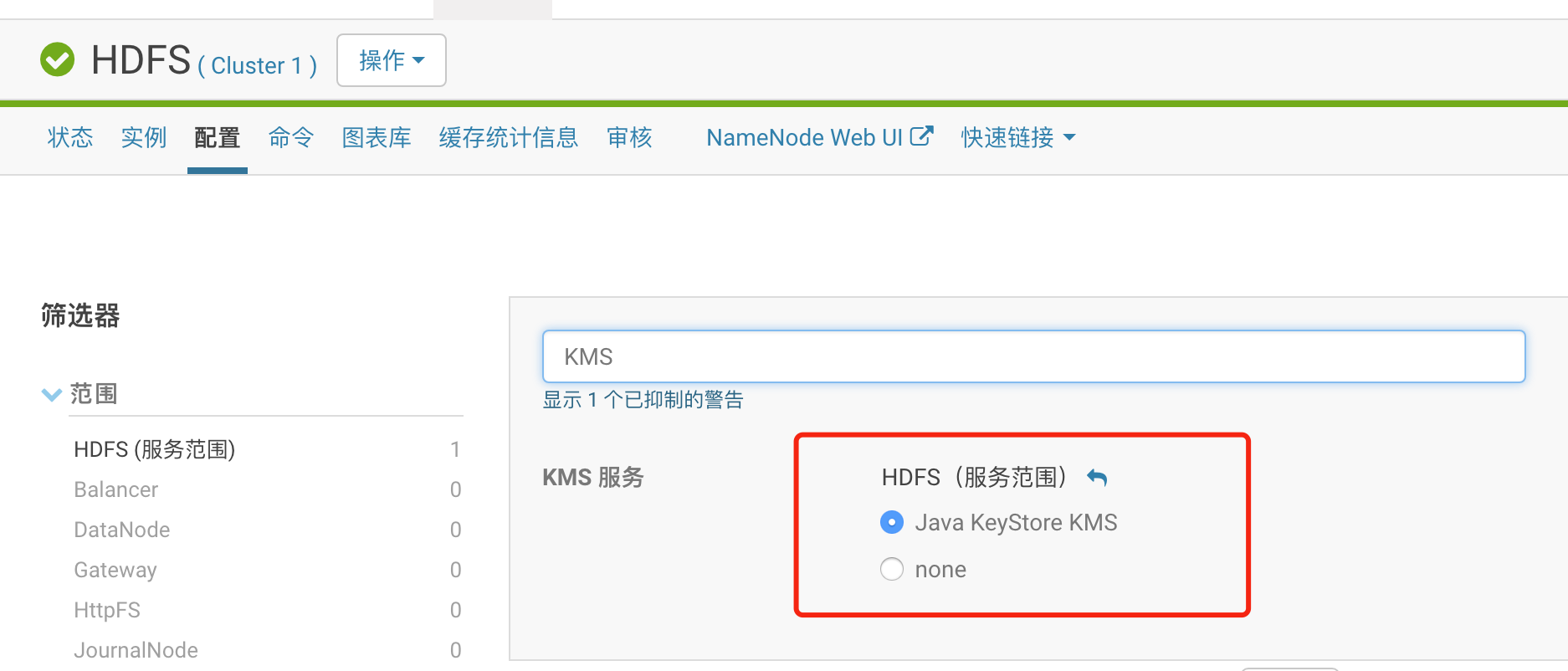
Kerberos上增加用户kms,kms用户具有管理密钥的权利
登陆kerberos服务器,用管理员用户进入命令行控制台增加用户,密码设置为kms
[root@node181 ~]# kadmin.local Authenticating as principal hbase/admin@HADOOP.COM with password. kadmin.local: add_principal kms@HADOOP.COM WARNING: no policy specified for kms@HADOOP.COM; defaulting to no policy Enter password for principal "kms@HADOOP.COM": Re-enter password for principal "kms@HADOOP.COM": Principal "kms@HADOOP.COM" created.在HDFS客户端登陆kerberos用户kms,创建密钥
[root@node86 ~]# kinit kms Password for kms@HADOOP.COM: kinit: Password incorrect while getting initial credentials [root@node86 ~]# kinit kms Password for kms@HADOOP.COM: [root@node86 ~]# hadoop key create testkey1 testkey1 has been successfully created with options Options{cipher='AES/CTR/NoPadding', bitLength=128, description='null', attributes=null}. KMSClientProvider[http://node183:16000/kms/v1/] has been updated. [root@node86 ~]# hadoop key list Listing keys for KeyProvider: KMSClientProvider[http://node183:16000/kms/v1/] testkey testkey1在HDFS客户端登陆Kerberos用户hdfs,创建文件夹/zwang/secret,并设置此文件夹为加密专区
[root@node86 ~]# kinit hdfs Password for hdfs@HADOOP.COM: [root@node86 ~]# hadoop fs -mkdir /zwang/secret [root@node86 ~]# hdfs crypto -createZone -keyName testkey1 -path /zwang/secret Added encryption zone /zwang/secret [root@node86 ~]# hdfs crypto -listZones /user/hdfs/.Trash/Current/zwang/secret testkey1 /zwang/secret testkey1在kms-acl.xml里增加属性配置,cm里通过界面配置完成
<property> <name>key.acl.testkey1.DECRYPT_EEK</name> <value>zwang</value> <description> ACL for decryptEncryptedKey operations. </description> </property>重启kms服务
测试加密文件
上传测试文件至/zwang/secret下面,报错。
 赋权zwang用户对secret的读写权限
赋权zwang用户对secret的读写权限[root@node86 ~]# hdfs dfs -setfacl -m user:zwang:rwx /zwang/secret [root@node86 ~]# hdfs dfs -getfacl /zwang/secret # file: /zwang/secret # owner: hdfs # group: supergroup user::rwx user:zwang:rwx group::r-x mask::rwx other::r-x登陆kerberos用户zwang,上传文件到/zwang/secret下面
[root@node86 ~]# kinit zwang Password for zwang@HADOOP.COM: [root@node86 ~]# hadoop fs -put 1.txt /zwang/secret [root@node86 ~]# hadoop fs -cat /zwang/secret/1.txt 1,jack,18 2,green,15除zwang用户外,换其他用户则无法查看文本内容,通过管理员用户hdfs查看相关文件,比较加密空间与非加密空间的数据备份即可看到加密与非加密的区别。 hdfs dfs -cat /.reserved/raw/zwang/secret/1.txt hdfs dfs -cat /.reserved/raw/zwang/tmp/1.txt

hive测试
通过hive建外部表,关联/zwang/tmp和/zwang/secret发现,加密空间对应的表无查询数据。
 通过cm界面增加hive使用testkey1密钥的权利,重启kms服务
通过cm界面增加hive使用testkey1密钥的权利,重启kms服务
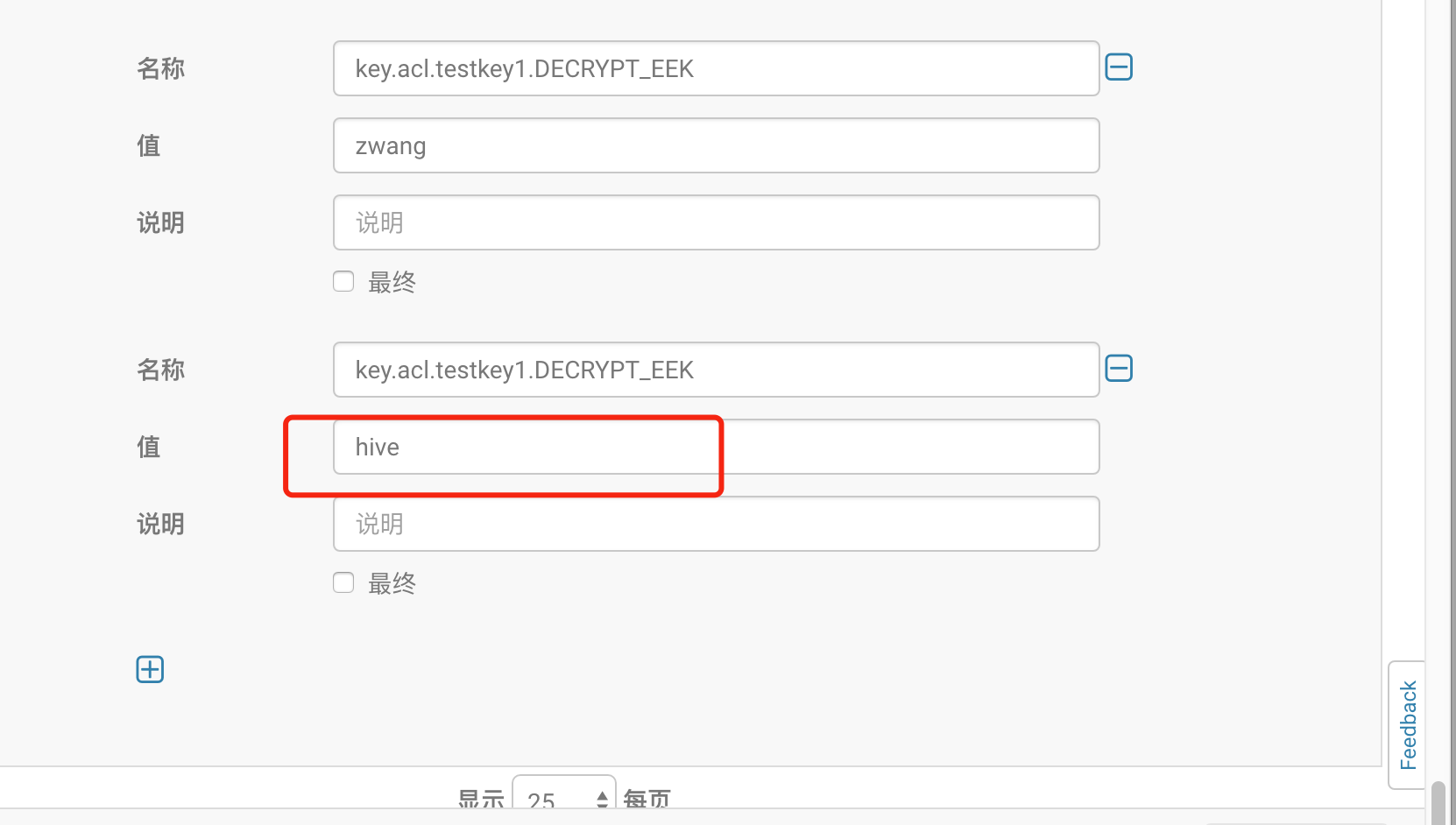 再次查询test1表,则数据可以正常显示。
再次查询test1表,则数据可以正常显示。

HBase透明服务器端加密
此功能提供透明加密,用于保护静态的HFile和WAL数据,使用双层密钥架构进行灵活且非侵入式的密钥轮换。首先需要修改HBase集群配置使其支持透明服务端加密,本文针对一个表中不同列簇设置不同的策略,以检验其加密的效果。具体过程请参考官网资料:http://archive.cloudera.com/cdh5/cdh/5/hbase-0.98.6-cdh5.3.3/book/hbase.encryption.server.html
为AES创建适当长度的密钥,alias设置为hbase,密码设置为ustcinfo
$ keytool -keystore /path/to/hbase/conf/hbase.jks \ -storetype jceks -storepass <密码> \ -genseckey -keyalg AES -keysize 128 \ -alias <alias>将生成的hbase.jks文件拷贝到所有hbase节点的/etc/conf/hbase目录下。 在CM控制台修改hbase-site.xml 的 HBase 服务高级配置代码段(安全阀),找到此配置
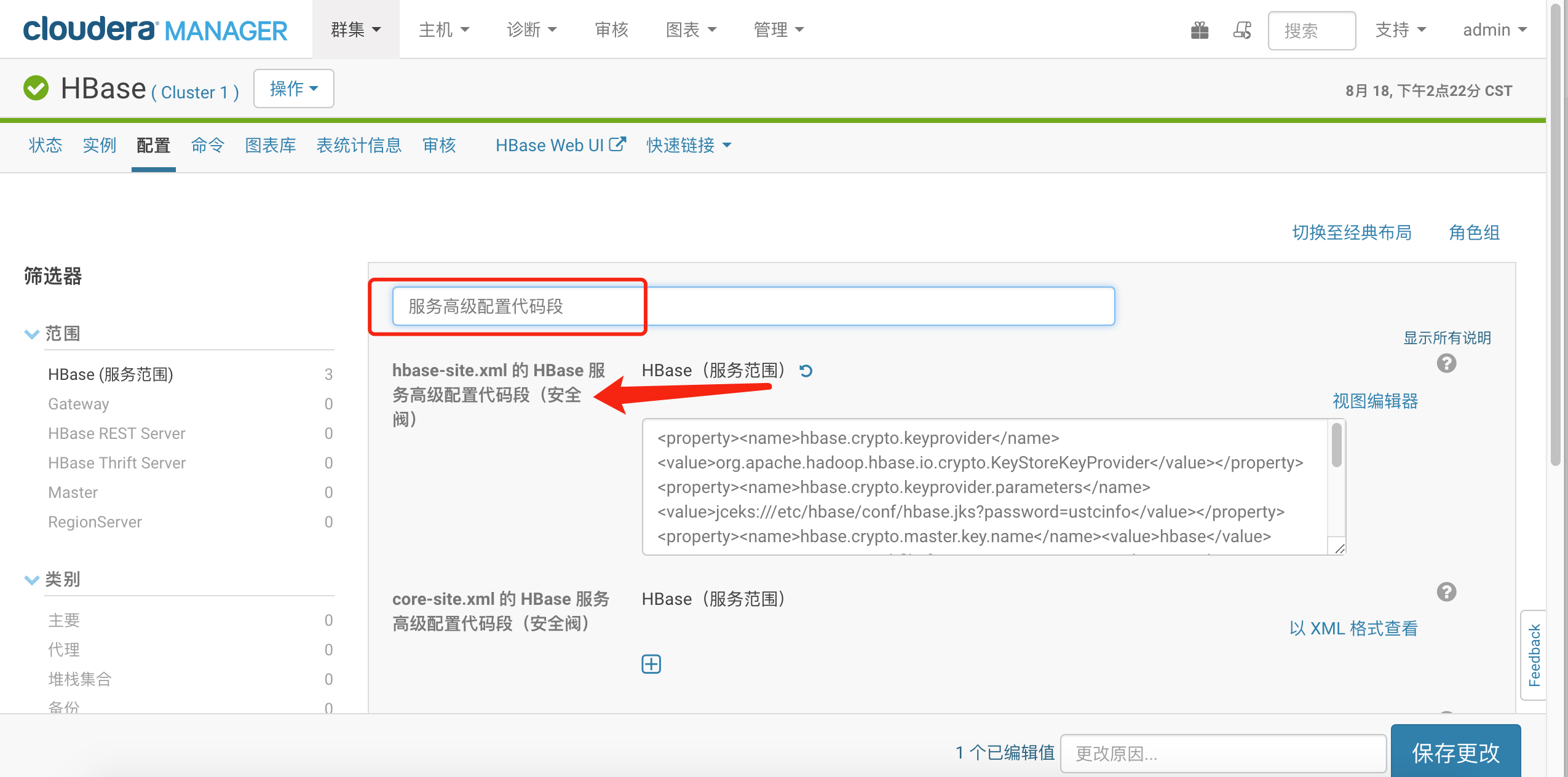 添加安全配置如下:
添加安全配置如下:<property><name>hbase.crypto.keyprovider</name><value>org.apache.hadoop.hbase.io.crypto.KeyStoreKeyProvider</value></property><property><name>hbase.crypto.keyprovider.parameters</name><value>jceks:///etc/hbase/conf/hbase.jks?password=ustcinfo</value></property><property><name>hbase.crypto.master.key.name</name><value>hbase</value></property><property><name>hfile.format.version</name><value>3</value></property><property><name>hbase.regionserver.hlog.reader.impl</name><value>org.apache.hadoop.hbase.regionserver.wal.SecureProtobufLogReader</value></property><property><name>hbase.regionserver.hlog.writer.impl</name><value>org.apache.hadoop.hbase.regionserver.wal.SecureProtobufLogWriter</value></property><property><name>hbase.regionserver.wal.encryption</name><value>true</value></property>重启HBase服务。 通过hbase用户登陆hbase shell,在建表时设置某个列簇加密
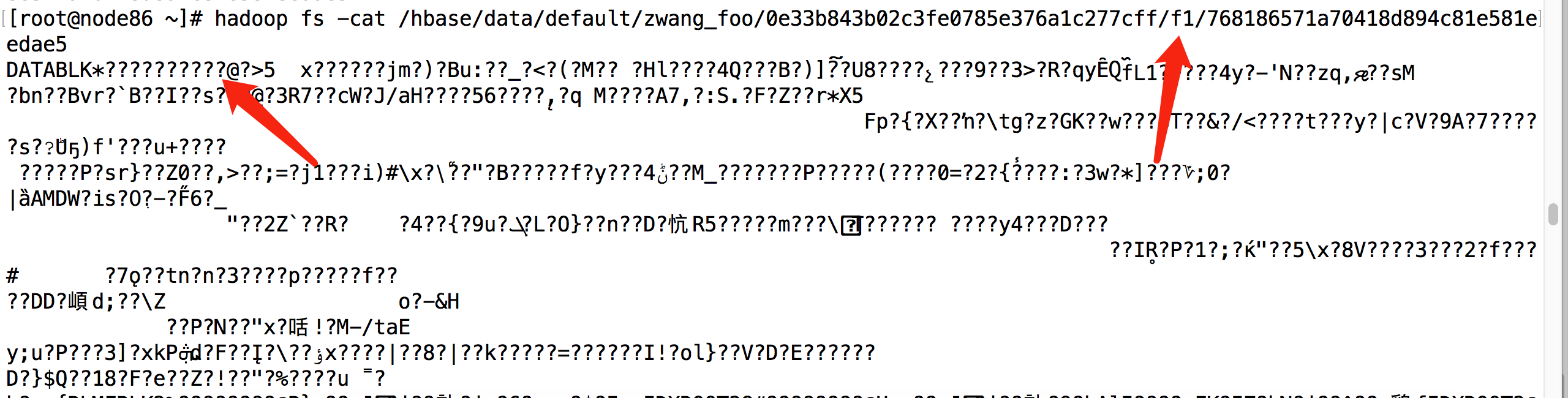
hbase(main):003:0> create 'zwang_foo',{ NAME=> 'f1',ENCRYPTION => 'AES'},{ NAME=> 'f2'} 0 row(s) in 2.2560 seconds => Hbase::Table - zwang_foo hbase(main):006:0> put 'zwang_foo','1','f1:address','wenqulu355 gaoxinqu hefeishi anhui china' 0 row(s) in 0.0080 seconds hbase(main):010:0> put 'zwang_foo','1','f2:address','wenqulu355 gaoxinqu hefeishi anhui china' 0 row(s) in 0.0160 seconds退出hbase shell ,查看hbase表对应的hfds文件,一开始看不到文件,可以重启下hbase,就可以到看到此表对应不同列簇的数据文件,一个处于AES加密状态,一个可以明显看到数据内容。 未加密列簇f2对应的hdfs文件:
 加密列簇f1对应的hdfs文件:
加密列簇f1对应的hdfs文件:
-
使用jeesite快速实现业务流程开发
企业内部协作管理的常见方式便是业务梳理并固化成流程,通过系统来实现工作流程的统一管理。笔者所在的运营商行业即有很多很多基于流程平台的业务系统,比如网络施工的统一管理、故障处理的流程管理。本文主要使用jeesit1.2.7版本进行的试验,可以在github和码云上找到此版本。
业务模型
CREATE TABLE `oa_loan` ( `id` varchar(64) COLLATE utf8_bin NOT NULL COMMENT '编号', `proc_ins_id` varchar(64) COLLATE utf8_bin DEFAULT NULL COMMENT '流程实例编号', `user_id` varchar(64) COLLATE utf8_bin DEFAULT NULL COMMENT '用户', `office_id` varchar(64) COLLATE utf8_bin DEFAULT NULL COMMENT '归属部门', `summary` varchar(64) COLLATE utf8_bin DEFAULT NULL COMMENT '借款事由', `fee` int(11) DEFAULT NULL COMMENT '借款金额', `reason` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '借款原因', `actbank` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '开户行', `actno` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '账号', `actname` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '账号名', `financial_text` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '财务预审', `lead_text` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '部门领导意见', `main_lead_text` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '总经理意见', `teller` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '出纳支付', `create_by` varchar(64) COLLATE utf8_bin NOT NULL COMMENT '创建者', `create_date` datetime NOT NULL COMMENT '创建时间', `update_by` varchar(64) COLLATE utf8_bin NOT NULL COMMENT '更新者', `update_date` datetime NOT NULL COMMENT '更新时间', `remarks` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '备注信息', `del_flag` char(1) COLLATE utf8_bin NOT NULL DEFAULT '0' COMMENT '删除标记', PRIMARY KEY (`id`), KEY `OA_TEST_AUDIT_del_flag` (`del_flag`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='借款流程测试表';表单开发
使用Jeesite的代码生成工具,生成业务单的增删查改界面。参考jeesite工程doc目录里的代码生成器应用。
流程设计
- 流程:财务审批-》部门领导审批-》总经理审批-》出纳支付
- 角色:普通用户角色 shock
财务初审人员 sd_zhb
部门经理角色 dept_leader 对应本部门中的c权限,jeesite中叫本部门管理员
总经理角色 shock
出纳员 sd_zhb - 流程设计要点:通过activiti流程设计器设计,参考jeesiste工程doc目录里的工作流的应用实例。重点有关联表单、每个环节的主键,每个环节继续执行下去的条件,设置成条件{pass==1}。每个环节的执行人配置,可以直接填写登陆名的,也可以设置角户组。本例中的部门领导采用的是传递变量的方式,在后台通过申请人的部门查找本部门中有本部门管理员角色的用户,将此用户设置成dept_leader,则流程流转到部门经理那边。其他流程处理人员通过设置登陆名或角色来实现流程流转。
- 代码修改:需要模仿工程的用户调薪模块对之前生成的表单代码进行修改,重点是增加流程审核的功能,并需要修改业务单表的ibatis配置文件。下面是通过部门名来查找部门经理名并在流程中设置部门经理变量的过程。
// 审核环节 if ("audit".equals(taskDefKey)) { oaLoan.setFinancialText(oaLoan.getAct().getComment()); if("yes".equals(oaLoan.getAct().getFlag())){ Office office = oaLoan.getOffice(); List<User> userList = systemService.findUser(new User(new Role("5"))); List<User> userList1 = systemService.findUserByOfficeId(office.getId()); userList.retainAll(userList1); vars.put("dept_leader", userList.get(0).getLoginName()); } dao.updateFinancialText(oaLoan); } else if ("audit2".equals(taskDefKey)) {
测试验证
功能做完后需要多找几个账号来测试验证,在测试过程中也发现了几个activit的表少了字段,也一并修改完成。具体代码参见https://github.com/shockw/jeemanage
-
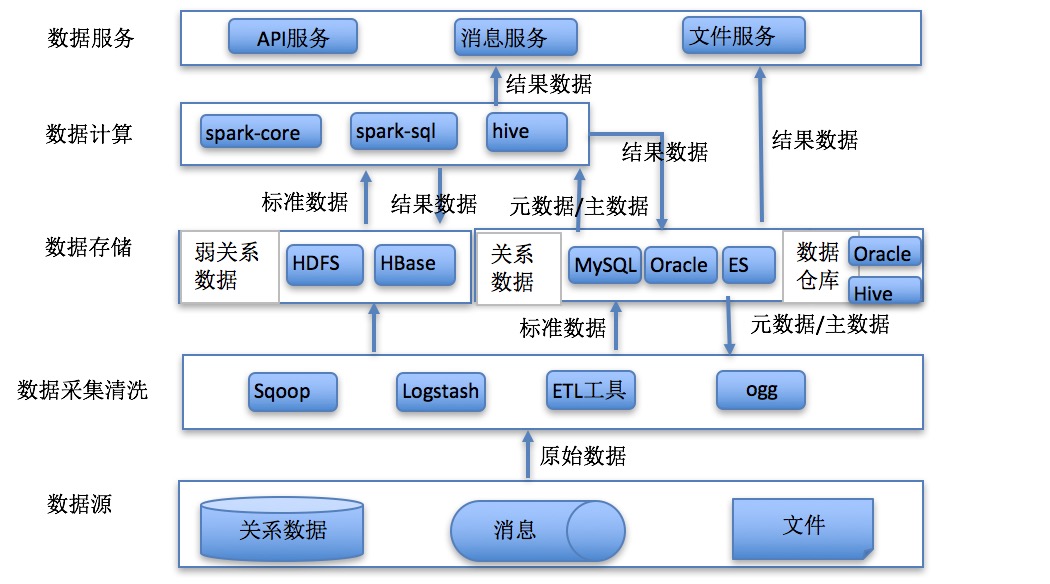
数据处理技术路径概览
根据笔者与某客户的聊天,就数据处理方面的技术方案总结梳理一下,主要是目前比较主流的技术方案进行了总结。由于笔者并不是专业的数据分析专家或是业务专家,以下方案仅供参考。
常见数据存储方式
生产数据结构化类型一般存储在Oracle或MySQL中,半结构化数据一般存储在文件或是NoSQL中。由于笔者没有从事过非结构化数据的技术方案,在此并不讨论非结构化数据的处理技术。在生产库后面一般都有一个历史库或叫分析库、归档库。主要是存储海量历史数据并能进行数据的统计分析及挖掘。

数据分类
下面数据的分类主要还是从客户比较熟悉的业务视角分类的,不同的场景可能区别比较大:

应用分类
原始数据指从数据源采集过来并没有加工的数据;标准数据指通过数据清洗转化的数据;结果数据指应用计算分析的结果:

统计分析
功能目标
通过业务规则对既有数据进行统计分析,获取目标结果的过程。
应用特点
数据来源广泛,既有实体数据、也有过程数据和配置数据,数据量大,计算量大,计算效率要求高。
方案概述
- Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要 读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的 情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系 统,简称HDFS,HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上,而且它提供高吞吐量来访 问应用程序的数据,适合那些有这超大数据集的应用程序。Hadoop的框架最核心的设计就是HDFS和 MapReduce。
- HBASE是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文 “Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System) 所提供的分布式数据存储一样,HBASE在Hadoop之上提供了类似于Bigtable的能力。HBASE是Apache的 Hadoop项目的子项目。HBASE不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。 另一个不同的是HBASE基于列的而不是基于行的模式。
- ETL过程是数据平台建设中最重要的步骤之一。ETL 规则设计和实施工作量巨大,是构建大数据核心处理 能力系统成败的关键。对于核心处理能力系统来说,ETL 主要工作是集成、转换、汇总等处理工作,最后将处理完的数据加载相关存储设备中。
技术架构
报表展示
功能目标
基于数据仓库,快速实现各类报表。
应用特点
侧重于快速的数据展示,主要用于数据决策系统。
方案概述
FineReport是帆软软件有限公司自主研发的一款企业级 web 报表软件产品,它“专业、简捷、灵活”, 仅需简单的拖拽操作便可以设计出复杂的中国式报表、参数查询报表、填报表、驾驶舱等,轻松搭建数据 决策分析系统。
技术架构

流式处理
功能目标
通过流式获取时间窗口数据,实时进行业务处理。
应用特点
海量数据采集,实时处理。例如采集性能数据根据规则进行实时预警。
方案概述
分布式流处理是对无边界数据集进行连续不断的处理、聚合和分析的过程,与MapReduce一样是一种通用计算框架,期望延迟在毫秒或者秒级别。
- Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,Kafka是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。针对不同业务,建立不同的主题用于传递各类消息。例如中兴LTE设备、华为传输设备原始数据可以分别建立不同的主题进行原始数据的流式处理。对于结果数据也可以通过主题向应用推送,从而实现实时应用。
- Spark streaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。数据可以从诸如Kafka,Flume,Kinesis或TCP套接字等许多源中提取,并且可以使用由诸如map,reduce,join或者 window等高级函数组成的复杂算法来处理。最后,处理后的数据可以推送到文件系统、数据库、实时仪表盘中。不同应用的计算任务可以使用spark集群的多租户进行资源配额管理。
技术架构
数据检索
功能目标
通过搜索各类应用系统的日志去定位系统问题,解决故障。
应用特点
海量结构化或半结构数据,存储周期短,实时性要求高,分布式采集,集中检索。
方案概述
ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats、Logstash、Elasticsearch、Kibana等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决方案。本文将会介绍ELK常见的架构以及相关问题解决。
- Filebeat:Filebeat是一款轻量级,占用服务资源非常少的数据收集引擎,它是ELK家族的新成员,可以代替Logstash作为在应用服务器端的日志收集引擎,支持将收集到的数据输出到Kafka,Redis等队列。
- Logstash:数据收集引擎,相较于Filebeat比较重量级,但它集成了大量的插件,支持丰富的数据源收集,对收集的数据可以过滤,分析,格式化日志格式。
- Elasticsearch:分布式数据搜索引擎,基于Apache Lucene实现,可集群,提供数据的集中式存储,分析,以及强大的数据搜索和聚合功能。
- Kibana:数据的可视化平台,通过该web平台可以实时的查看 Elasticsearch 中的相关数据,并提供了丰富的图表统计功能。
技术架构

数据挖掘
功能目标
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
应用特点
主要使用海量结构化数据,对数据进行清洗,建立探索模型,使用分类、聚类、关联、回归等算法实现模型的生成。其具有一定不确定性,主要用于预测,有一定的失败概率。
方案概述
- Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python包含有非常多的算法框架来实现数据挖掘和机器学习,比如scikit-learn,scikit-learn是一个基于NumPy, SciPy, Matplotlib的开源机器学习工具包,主要涵盖分类,回归和聚类算法,例如SVM, 逻辑回归,朴素贝叶斯,随机森林,k-means等算法。PySpark 是 Spark 为 Python 开发者提供的 API。
- MLlib是Spark的机器学习(ML)库。旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化和高层的管道API。
技术架构

-
浅谈从单体应用到业务中台架构的演变
根据笔者见过的项目情况,就企业应用的技术架构进行一些粗浅分析。业务中台的理念来源于SOA思想,经过阿里等互联网公司发扬光大,形成实际可行的技术方案。事实上行业软件里早就有了SOA架构的实践,不过从实际上来看,笔者所在的运营商行业其实发展并不好,经常是投资大,收益小。业务的设计和IT人员的水平关系很大,大多设计一个集中式的ESB管理所有服务,但服务很少是从业务角度考虑,大多只是一个技术接口,没有体现出SOA的本质,更谈不上其效果。
科学的方法
不管是什么技术方案,都不是统一天下的方案,不同的场景总要有适合的方案。我们总是要寻找切实高效的方案,而不是人云亦云,领导说好就是好,客户说好就是好。事实上我们需要有自己独立的思考,在业务较简单时,很明显不适宜上复杂的方案。
单体应用
企业单体应用一般就是一个web程序和一个数据库。比较常见的技术方案如下:

业务中台架构
当业务变化很快,且系统复杂后,就需要将系统拆分成多个业务中心,拆分的目的就是抽象业务,形成高内聚低耦合的服务中心,这样服务支撑会更迅速,开发迭代的速度会提高,另外每个中心的开发规模会变小,大家会更专业。每个服务中心都会需要架构师、开发人员、ued人员、dba与运维等。复杂的系统的响应总是很慢,由于业务之间的耦合,导致新增一个功能漫长且容易出错。只有最熟悉企业业务的人参与,才可能从业务角度对系统进行架构。公共技术的服务剥离实际上并没有什么成效,现在很多企业IT的现状是懂技术的人不懂业务,懂业务的人不懂技术,这会严重影响企业的架构水平。下面是著名的阿里巴巴中台战略思想与架构实战中的共享服务架构:

技术栈
层级\架构 业务架构 技术架构 应用层 天猫、淘宝、聚划算、手机淘宝、口碑等 Html5/Js、移动应用、表单、流程 服务层 用户中心、商品中心、交易中心、评价中心等 微服务(spring boot)、负载均衡(haproxy/nginx)、弹性伸缩(docker)、服务熔断(Hystrix)、链式跟踪(pinpoint) 数据层 用户模型、商品模型、交易模型 Oracle、MySQL、分布式数据库(Drds/Mycat) 业务中台架构的重要特征
- 服务显性化管理,服务一旦部署,所有人可见服务并且能够看到服务API并进行测试,比如swaggerui即可显性化服务接口的调用协议。所有人都可以看到服务列表。
- 服务的全面监控,通过统一的日志拦截,记录所有服务的关联并跟踪其成功失败、耗时等情况,实现链式监控。
- 服务有个统一的入口,系统间均可以通过这个入口统一调用所有服务。
- 业务封装在服务中心,服务的抽象需要有原子性。应用重点关注服务的使用和前端的交互,重点通过服务编排实现应用功能。
- 业务服务可以实现弹性伸缩,比如瞬间增加N个节点以提高其性能。
- 数据层需要打好基础,一般需要有统一的分布式文件系统、统一的分布式数据库。文件系统里有分针对大文件,比如hdfs,也有针对小文件,比如TFS。
- 系统对外提供能力,可以通过API网关,重点实现权限的控制。
-
使用pyspider实现抓取合肥房产局数据Demo