Welcome to shock's blog
一路走来,且行且珍惜。-
数据平台浅谈
概念解析
什么是数据平台?和数据工厂、数据中台、数据仓库、数据集市、数据工厂有什么区别。我们来看下相关文章里对上述概念的理解。
数据工厂
数据工厂通过实时多源数据集成,柔性数据治理工艺、智能数据加工、综合数据服务,帮助客户降本增效、高效利用数据、充分挖掘数据资产价值,实现企业智能化生产、监管、运营。
数据中台
数据中台本身没有严格的学术定义,其具体特征包括支持多个前台业务且具备业务属性的共性数据能力体系。
数据仓库
数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。数据仓库具备以下4个特征。
- 面向主题:数据仓库都是基于某个明确主题,仅需要与该主题相关的数据,其他的无关细节数据将被排除掉
- 集成的:从不同的数据源采集数据到同一个数据源,此过程会有一些ETL操作
- 随时间变化:关键数据隐式或显式的基于时间变化
- 数据仓库的数据是不可更新的:数据装入以后一般只进行查询操作,没有传统数据库的增删改操作。数据仓库的数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据,而不是联机处理的数据。

数据集市
数据集市(Data Mart),也叫数据市场,为满足特定的部门或者用户需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
数据集市,迎合了专业用户群体的特殊需求,包括分析、内容、表现,以及易用性方面。
数据集市,是企业级数据仓库的一个子集,主要面向部门级业务,只面向某个特定的主题。
数据集市数据来源于企业范围的数据库、专业的数据仓库。
数据集市的特征:规模小;特定的应用;面向部门;由业务部门定义、设计和开发;业务部门管理和维护;快速实现;购买较便宜;投资快速回收;工具集的紧密集成;提供更详细的、预先存在的、数据仓库的摘要子集;可升级到完整的数据仓库。
与数据仓库的区别:指标 数据仓库 数据集市 数据来源 遗留系统、外部数据 数据仓库 范围 企业级 部门级或工作组级 主题 企业主题 部门或特殊的分析主题 数据粒度 最细的粒度 较粗的粒度 数据结构 规范化结构、星型模型、雪花模型 星型模型、雪花模型 历史数据 大量的历史数据 适度的历史数据 优化 处理海量数据/数据探索 便于访问和分析/快速查询 索引 高度索引 高度索引 相关关系分析
数据平台更多强调的是IT技术,而非业务或数据。中台包括技术、数据和业务。数据仓库和集市更多强调的是数据。数据平台和数据工厂的概念相似,更多的是为数据开发人员、管理人员、数据应用人员提供一站式的工具链,快速完成数据沉淀和对外能力透出的流水线工作,实现数据智能化生产运营。
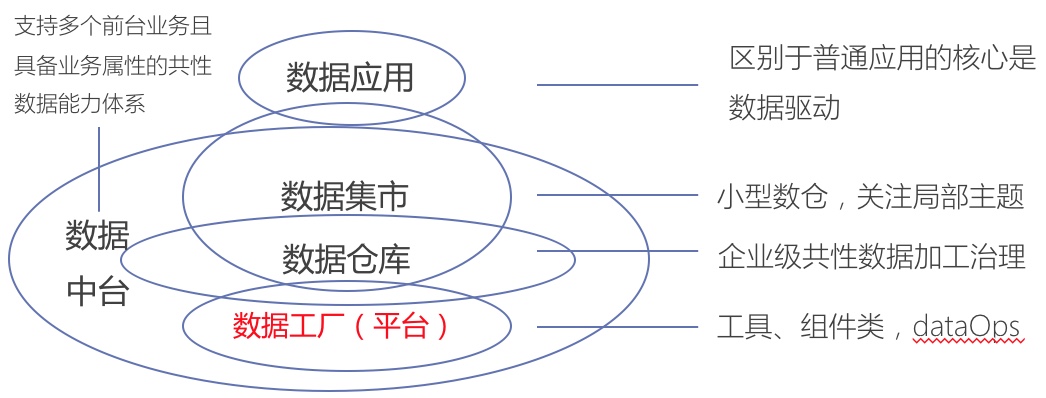
平台架构
数据平台提供一系列数据集成、数据治理、数据加工、数据共享的工具组件,打造核心数据体系,为上层业务中心和应用提供二次建模的智慧运营数据,驱动业务生产。
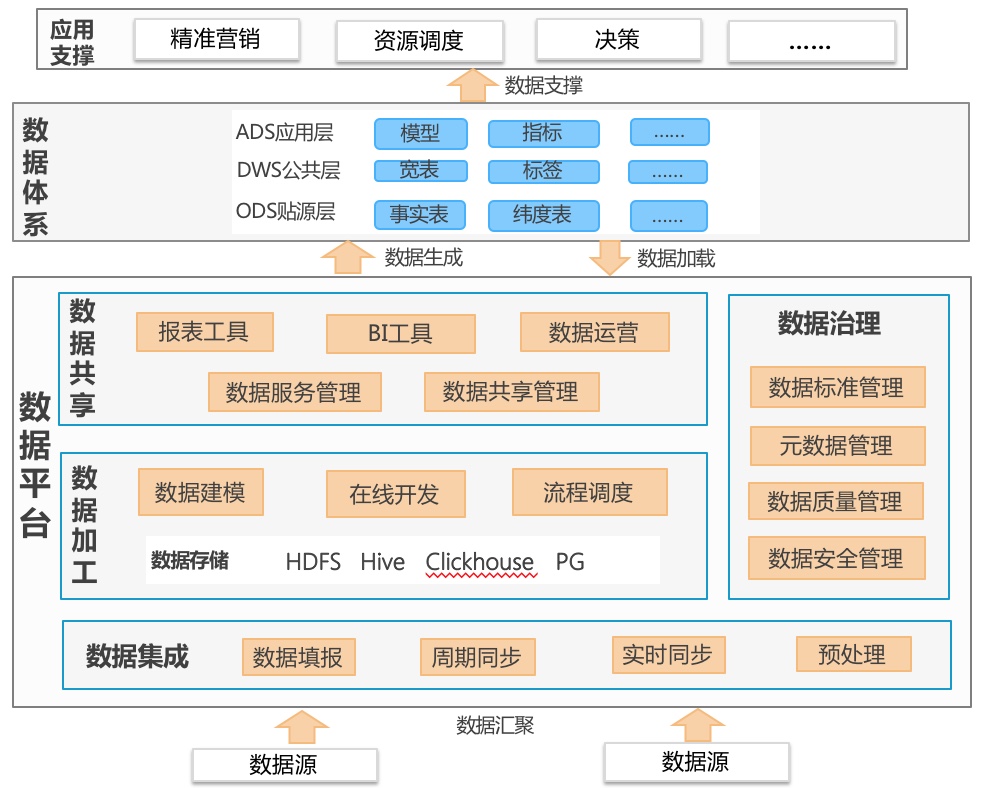
-
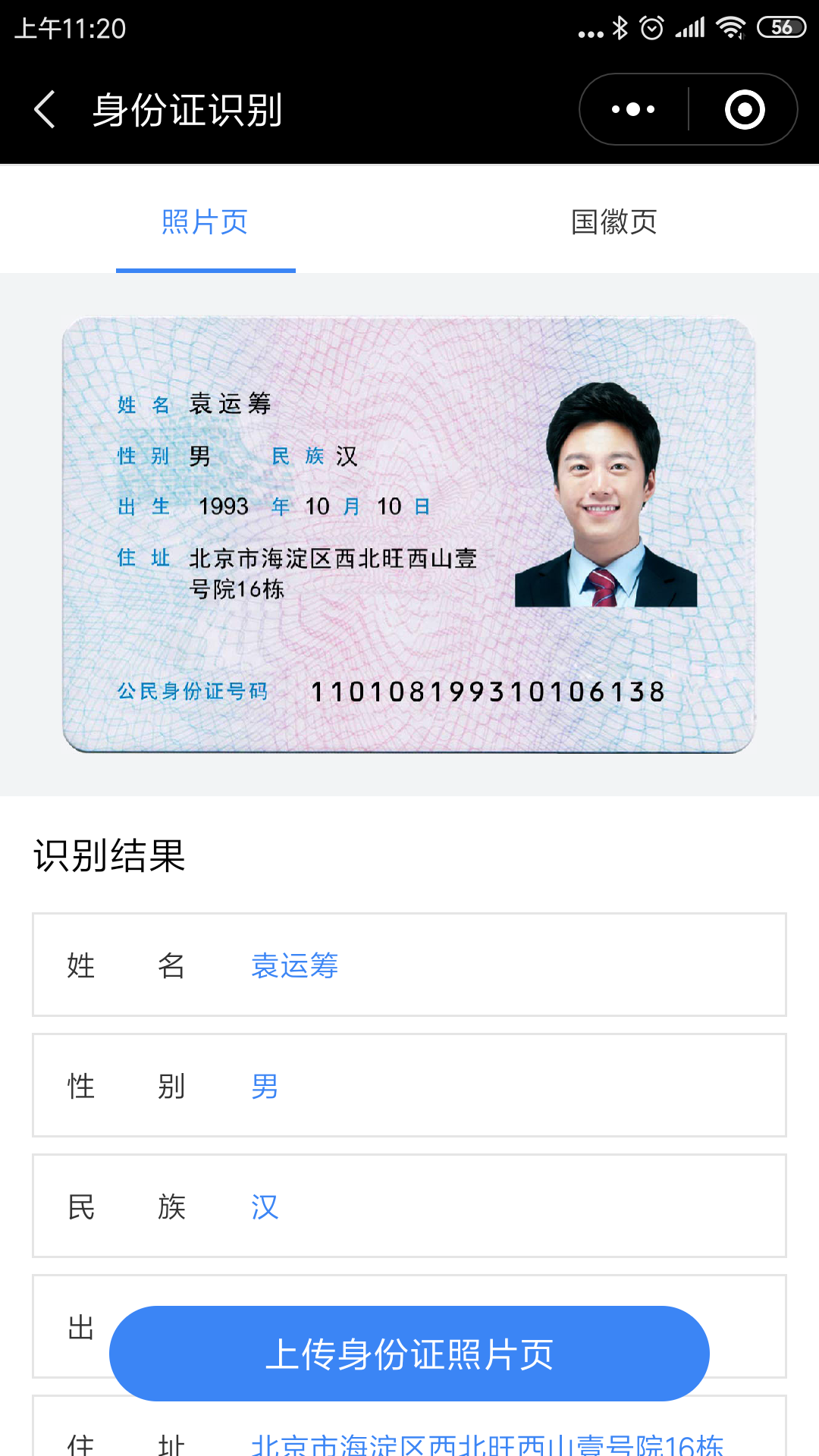
基于opencv和tesseract实现身份证扫描件的身份证号码提取试验
身份证识别技术目前已经非常成熟,大厂家都发布了相应的api支撑应用开发,同类的技术主要有发票识别、车牌号识别、驾证识别等,主要特点是基于图像技术提取其中的OCR字符,再完成OCR文字识别。
试验工程链接
主要过程如下:
- 获取身份证号区域:image-》灰度=》反色=》膨胀=》findContours
- 数字识别:采用tesseract识别,通过trainfont.py获得traineddata
开发环境安装
本机为mac,参考文档,先安装tesseract环境,python里面通过pytesseract调用tesseract能力。
- 安装anaconda python3.6版本
- 进入anaconda后台,安装opencv,conda install -c https://conda.binstar.org/menpo opencv
- 安装依赖 brew install leptonica
- 安装tesseract brew install tesseract
- 安装tesseract的python接口,pip3 install pytesseract
在python代码引用pytesseract,但实际上可能引用不到,需要修改pytesseract.py中的变量,方便调用tesseract类库。直接修改pytesseract.py文件。
tesseract_cmd = '/usr/local/Cellar/tesseract/4.0.0_1/bin/tesseract'在实际使用中需要用到字体模型,需要指定模型位置。修改ocr.py文件
tessdata_dir_config = '-c tessedit_char_whitelist=0123456789X --tessdata-dir "/usr/local/Cellar/tesseract/4.0.0_1/share/tessdata"' result = pytesseract.image_to_string(image, lang='ocrb', config=tessdata_dir_config)OCR代码测试
简单写一段代码测试,即可体验OCR识别的能力。
from PIL import Image from pytesseract import * image = Image.open('test0.png') #识别过程 text = image_to_string(image) print(text)身份证号码识别测试
运行ocr.py,即可测试身份证识别,需要将tessdata下面的模型拷到指定的位置,并在代码里指定需要使用的模型位置。
效果
简单写一个页面,即可看到ocr识别的效果。

总结
目前OCR识别技术已经很成熟,研发人员可以针对特定场景进行定制模型的训练与优化,实现能力私有化部署,比如实现特定票据、合同的识别等。技术的关键在于对于图像的处理和OCR字体识别模型的训练,目前tesseract针对中文字体(字体种类也非常 多)还不是很成熟,但可以通过定制化的方式进行优化。后面可以加大这方面能力的研发。在小程序里也可以定制一个身份证拍照的框,在拍照完成后在线显示身份证信息,达到体验的目的,为了安全考虑可以自动加上水印,或者为了安全起见,针对上传的照片或特定的照片识别即可。目前各类互联网的实名认证也是类似的场景。运营商内部进行实名制验证的核心能力就是身份证号码的识别和人证合一的人脸比对能力。这个能力成熟后即可大大减轻用户实名制审核的人工劳动量。
-
在jeesite工程中集成quartz-web用于定时任务的管理
参考链接
https://www.w3cschool.cn/quartz_doc/
quartz简介
Quartz 是一个完全由 Java 编写的开源作业调度框架,为在 Java 应用程序中进行作业调度提供了简单却强大的机制。 Quartz 可以与 J2EE 与 J2SE 应用程序相结合也可以单独使用。 Quartz 允许程序开发人员根据时间的间隔来调度作业。 Quartz 实现了作业和触发器的多对多的关系,还能把多个作业与不同的触发器关联。
核心概念
Job、JobDetail、Trigger、Scheduler
实践环境
- 使用spring-quartz,通过在xml文件中配置一个调度器。
- 使用mysql作为quartz的中心管理节点,所有java应用都与mysql相连,实现任务可以在一个高可用环境中运行,且只运行一次。如果有一个节点宕机的情况下,则其他节点仍然可以执行任务。
- 所有的任务均持久化到mysql中,jobDetail和Trigger均可以很方便的管理。
为什么使用quartz-web
quartz-web是一款开源的管理软件,通过web和接口的方式来管理调度器中的所有任务和定时器。可以很方便地集成到spring项目中。
配置过程
web.xml增加quartz-web的servlet配置
在pom文件中增加quartz-web的依赖
<dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>2.2.1</version> </dependency> <dependency> <groupId>com.github.quartzweb</groupId> <artifactId>quartz-web</artifactId> <version>1.2.0</version> </dependency>web.xml增加quartz-web的servlet配置
<!-- quartzweb --> <servlet> <servlet-name>quartzweb</servlet-name> <servlet-class>com.github.quartzweb.http.QuartzWebServlet</servlet-class> </servlet> <!--配置url--> <servlet-mapping> <servlet-name>quartzweb</servlet-name> <url-pattern>/quartzweb/*</url-pattern> </servlet-mapping>增加一个quartz的属性文件配置
在resources目录下面新建一个目录schedule,在目录下面新建文件quartz-cluster.properties。
#============================================================================ # Configure Main Scheduler Properties #============================================================================ org.quartz.scheduler.instanceName = ClusteredScheduler org.quartz.scheduler.instanceId = AUTO org.quartz.scheduler.skipUpdateCheck = true #============================================================================ # Configure ThreadPool #============================================================================ org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool org.quartz.threadPool.threadCount = 5 org.quartz.threadPool.threadPriority = 5 #============================================================================ # Configure JobStore #============================================================================ org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate org.quartz.jobStore.misfireThreshold = 60000 org.quartz.jobStore.useProperties = false org.quartz.jobStore.tablePrefix = QRTZ_ #Cluster setting org.quartz.jobStore.isClustered = true org.quartz.jobStore.clusterCheckinInterval = 15000增加一个spring-context-quartz.xml的spring配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/taskhttp://www.springframework.org/schema/task/spring-task.xsd"> <description>spring任务调度,quartz任务调度</description> <!-- 计划任务配置,用 @Service @Lazy(false)标注类,用@Scheduled(cron = "0 0 2 * * ?")标注方法 --> <task:executor id="executor" pool-size="10"/> <task:scheduler id="scheduler" pool-size="10"/> <task:annotation-driven scheduler="scheduler" executor="executor" proxy-target-class="true"/> <bean id="clusterQuartzScheduler" class="org.springframework.scheduling.quartz.SchedulerFactoryBean"> <!-- quartz配置文件路径, 指向cluster配置 --> <property name="configLocation" value="classpath:schedule/quartz-cluster.properties" /> <!-- 启动时延期5秒开始任务 --> <property name="startupDelay" value="5" /> <!-- 保存Job数据到数据库所需的数据源 --> <property name="dataSource" ref="dataSource" /> <!-- Job接受applicationContext的成员变量名 --> <property name="applicationContextSchedulerContextKey" value="applicationContext" /> <!-- 修改job时,更新到数据库 --> <property name="overwriteExistingJobs" value="true" /> </bean> <!--设置系统管理器,必须使用getInstance()初始化实例,系统整体设计管理器全部为单例--> <bean class="com.github.quartzweb.manager.quartz.QuartzManager" factory-method="getInstance"> <!--设置scheduler集合--> <property name="schedulers"> <list> <ref bean="clusterQuartzScheduler" /> </list> </property> <!--设置是否查找scheduler仓库,false--> <property name="lookupSchedulerRepository" value="false"/> <!--是否使用默认scheduler--> <property name="useDefaultScheduler" value="false"/> </bean> <!--设置bean管理器,通过spring的applicationContext获取--> <bean id="springQuartzBeanManager" class="com.github.quartzweb.manager.bean.SpringQuartzBeanManager"> <property name="priority" value="1" /> </bean> <!--声明bean管理器门面,必须使用getInstance()初始化实例--> <bean id="quartzBeanManagerFacade" class="com.github.quartzweb.manager.bean.QuartzBeanManagerFacade" factory-method="getInstance"> <!--设置管理器,根据优先级排序--> <property name="quartzBeanManagers"> <list> <ref bean="springQuartzBeanManager"/> </list> </property> <!--是否启用默认bean管理器--> <property name="useDefaultQuartzBeanManager" value="false"/> </bean> </beans>效果
启动web工程后,输入http://ip:port/应用名/quartzweb,即可打开quartz管理界面
quartz任务示例
下面是一个quartzJob的示例
package com.reache.jeemanage.test.job; import java.util.Date; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.scheduling.quartz.QuartzJobBean; public class JobDemo extends QuartzJobBean { private static Logger logger = LoggerFactory.getLogger(JobDemo.class); @Override protected void executeInternal(JobExecutionContext ctx) throws JobExecutionException { logger.info("线程id:" + Thread.currentThread().getId() + " 时间:" + new Date()); } }关于不通过web界面进行任务管理的方式
此种方式下,也可以通过xml配置的方式完成任务配置,需要注意的是只要任务配置过后并启动一次,则后面即使删除配置,任务仍会存在,原因是任务已经持久化到数据库。下面是一个配置示例
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/taskhttp://www.springframework.org/schema/task/spring-task.xsd"> <description>spring任务调度,quartz任务调度</description> <task:annotation-driven executor="quartzTaskExecutor" /> <task:executor id="quartzTaskExecutor" keep-alive="900" pool-size="10" queue-capacity="20" /> <bean id="clusterQuartzScheduler" class="org.springframework.scheduling.quartz.SchedulerFactoryBean"> <!-- quartz配置文件路径, 指向cluster配置 --> <property name="configLocation" value="classpath:schedule/quartz-cluster.properties" /> <!-- 启动时延期5秒开始任务 --> <property name="startupDelay" value="5" /> <!-- 保存Job数据到数据库所需的数据源 --> <property name="dataSource" ref="dataSource" /> <!-- Job接受applicationContext的成员变量名 --> <property name="applicationContextSchedulerContextKey" value="applicationContext" /> <!-- 修改job时,更新到数据库 --> <property name="overwriteExistingJobs" value="true" /> <!-- Triggers集成 --> <property name="triggers"> <list> <ref bean="heartBeatTrigger" /> </list> </property> </bean> <!-- 定时任务 --> <bean id="heartBeatTrigger" class="org.springframework.scheduling.quartz.CronTriggerFactoryBean"> <property name="jobDetail" ref="heartBeatJobDetail" /> <!-- 每5秒执行一次 --> <property name="cronExpression" value="*/5 * * * * ? " /> </bean> <bean id="heartBeatJobDetail" class="org.springframework.scheduling.quartz.JobDetailFactoryBean"> <property name="durability" value="true" /> <property name="jobClass" value="com.ustcinfo.ishare.bdp.modules.transfer.resource.job.HeartBeatJob" /> </bean> </beans>
-
关于无向图中的路径搜索试验
博客链接
https://www.cnblogs.com/hlongch/p/5892594.html
问题分析
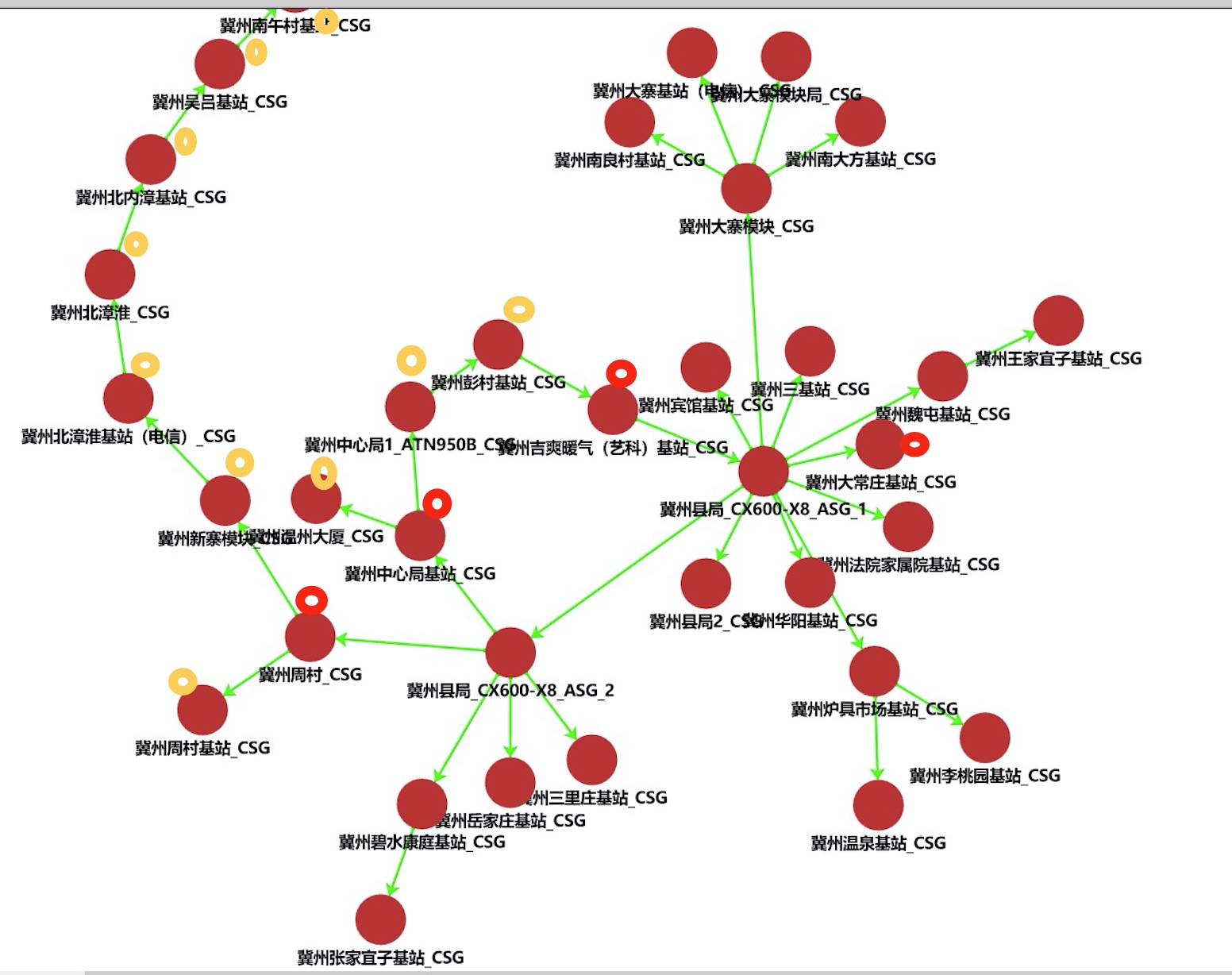
在运营商的传输电路中,每个县区会有两台ASG传输设备用于用户接入侧到骨干传输网的连接,在ASG下面又挂有多个CSG设备,从而形成县区的传输电路。如果某个CSG设备脱管,则可能会影响到其他CSG设备,从而影响多个小区上网。如何根据脱管的CSG设备计算出受影响的网络设备? 本质上来说这是一个无向图的路径搜索问题,即当有脱管设备时,将此设备与其他节点的关系删除,遍历所有设备,如果设备可以找到路径到达其中任何一台ASG设备,则认为此设备没有问题,否则认为此节点也受影响
代码
根据网上代码例子,用现实的数据测试了一下计算效果,速度上还可以接受,本例子中节点数35个。本例中提供了一个方法封装。
import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.Stack; /** * 无向无权无环图<br/> * 寻找起点到终点的所有路径 定义 * 根据节点间的关系及脱管节点,给出所有受影响的节点数 */ public class GrfAllEdge { // 图的顶点总数 private int total; // 各顶点基本信息 private String[] nodes; // 脱管的节点 private List<String> nodesUn; // asg1在节点中的索引 private int asg1Index; // asg2在节点中的索引 private int asg2Index; // 图的邻接矩阵 private int[][] matirx; /** * * @param total 节点总数 * @param nodesA 节点数组 * @param nodesZ 每节节点关联的节点目标关系 * @param asg1Index asg1节点在节点数组中的索引位置 * @param asg2Index asg2节点在节点数组中的索引位置 * @param nodesUn 脱管的节点列表 */ public GrfAllEdge(int total, String[] nodesA, String[] nodesZ, int asg1Index, int asg2Index, List<String> nodesUn) { this.total = total; this.nodes = nodesA; this.matirx = new int[total][total]; this.asg1Index = asg1Index; this.asg2Index = asg2Index; this.nodesUn = nodesUn; for (int i = 0; i < total; i++) { String node = nodesZ[i]; for (int j = 0; j < total; j++) { if (node == nodesA[j]) { this.matirx[i][j] = 1; this.matirx[j][i] = 1; break; } } } // 脱管节点与其他节点设置无关系 for (int i = 0; i < total; i++) { if (this.nodesUn.contains(nodes[i])) { for (int j = 0; j < total; j++) { this.matirx[j][i] = 0; this.matirx[i][j] = 0; } } } // 节点自身不会相连 for (int i = 0; i < this.total; i++) { this.matirx[i][i] = 0; } // 设置两个asg节点间无关联 this.matirx[asg1Index][asg2Index] = 0; this.matirx[asg2Index][asg1Index] = 0; } /** * 获取每条路径的经过节点 * * @param stack * @param k * @return */ private String getStackLink(Stack<Integer> stack, int k) { StringBuilder sb = new StringBuilder(); for (Integer i : stack) { sb.append(this.nodes[i] + ","); } sb.append(this.nodes[k] + ","); return sb.toString(); } /** * 寻找起点到终点的所有路径 * * @param underTop 紧挨着栈顶的下边的元素 * @param goal 目标 * @param stack */ private void dfsStack(int underTop, int goal, Stack<Integer> stack, List<String> lines) { if (stack.isEmpty()) { return; } // 访问栈顶元素,但不弹出 int k = stack.peek().intValue(); // 紧挨着栈顶的下边的元素 // int uk = underTop; if (k == goal) { // System.out.print("\n起点与终点不能相同"); return; } // 对栈顶的邻接点依次递归调用,进行深度遍历 for (int i = 0; i < this.total; i++) { // 有边,并且不在左上到右下的中心线上 if (this.matirx[k][i] == 1 && k != i) { // 排除环路 if (stack.contains(i)) { // 由某顶点A,深度访问其邻接点B时,由于是无向图,所以存在B到A的路径,在环路中,我们要排除这种情况 // 严格的请,这种情况也是一个环 // if (i != uk) { // System.out.print("\n有环:"); // this.printStack(stack, i); // } continue; } // 打印路径 if (i == goal) { //System.out.print("\n路径:"); lines.add(getStackLink(stack, i)); continue; } // 深度遍历 stack.push(i); dfsStack(k, goal, stack, lines); } } stack.pop(); } /** * 打印节点关系矩阵图 */ public void printMatrix() { System.out.println("----------------- matrix -----------------"); for (int i = 0; i < this.total; i++) { System.out.print(this.nodes[i] + "|"); } System.out.println(); for (int i = 0; i < this.total; i++) { System.out.print(" " + this.nodes[i] + "|"); for (int j = 0; j < this.total; j++) { System.out.print(this.matirx[i][j] + "-"); } System.out.print("\n"); } System.out.println("----------------- matrix -----------------"); } /** * * @return 返回受影响的节点,不包括asg节点,如果ASG节点不正常,则此方法不适用 */ public List<String> unreachableNodeAll() { List<String> unreachableNodeList = new ArrayList<String>(); // 查询节点关联到主ASG节点 for (int i = 0; i < this.total; i++) { int origin = i; int goal1 = this.asg1Index; Stack<Integer> stack1 = new Stack<Integer>(); List<String> lines1 = new ArrayList<String>(); stack1.push(origin); this.dfsStack(-1, goal1, stack1, lines1); int goal2 = this.asg2Index; Stack<Integer> stack2 = new Stack<Integer>(); List<String> lines2 = new ArrayList<String>(); stack2.push(origin); this.dfsStack(-1, goal2, stack2, lines2); if (lines1.size() < 1 && lines2.size() < 1 && i != goal1 && i != goal2) { unreachableNodeList.add(this.nodes[i]); } } return unreachableNodeList; } public static void main(String[] args) { String[] nodesA = new String[] { "冀州县局2_CSG", "冀州大寨模块_CSG", "冀州大寨模块局_CSG", "冀州南大方基站_CSG", "冀州南良村基站_CSG", "冀州大寨基站(电信)_CSG", "冀州宾馆基站_CSG", "冀州三基站_CSG", "冀州魏屯基站_CSG", "冀州王家宜子基站_CSG", "冀州炉具市场基站_CSG", "冀州李桃园基站_CSG", "冀州温泉基站_CSG", "冀州大常庄基站_CSG", "冀州法院家属院基站_CSG", "冀州华阳基站_CSG", "冀州县局_CX600-X8_ASG_2", "冀州周村_CSG", "冀州周村基站_CSG", "冀州新寨模块_CSG", "冀州北漳淮基站(电信)_CSG", "冀州北漳淮_CSG", "冀州北内漳基站_CSG", "冀州吴吕基站_CSG", "冀州南午村基站_CSG", "冀州三里庄基站_CSG", "冀州中心局基站_CSG", "冀州中心局1_ATN950B_CSG", "冀州彭村基站_CSG", "冀州吉爽暖气(艺科)基站_CSG", "冀州县局_CX600-X8_ASG_1", "冀州温州大厦_CSG", "冀州碧水康庭基站_CSG", "冀州张家宜子基站_CSG", "冀州岳家庄基站_CSG" }; String[] nodesZ = new String[] { "冀州县局_CX600-X8_ASG_1", "冀州县局_CX600-X8_ASG_1", "冀州大寨模块_CSG", "冀州大寨模块_CSG", "冀州大寨模块_CSG", "冀州大寨模块_CSG", "冀州县局_CX600-X8_ASG_1", "冀州县局_CX600-X8_ASG_1", "冀州县局_CX600-X8_ASG_1", "冀州魏屯基站_CSG", "冀州县局_CX600-X8_ASG_1", "冀州炉具市场基站_CSG", "冀州炉具市场基站_CSG", "冀州县局_CX600-X8_ASG_1", "冀州县局_CX600-X8_ASG_1", "冀州县局_CX600-X8_ASG_1", "冀州县局_CX600-X8_ASG_1", "冀州县局_CX600-X8_ASG_2", "冀州周村_CSG", "冀州周村_CSG", "冀州新寨模块_CSG", "冀州北漳淮基站(电信)_CSG", "冀州北漳淮_CSG", "冀州北内漳基站_CSG", "冀州吴吕基站_CSG", "冀州县局_CX600-X8_ASG_2", "冀州县局_CX600-X8_ASG_2", "冀州中心局基站_CSG", "冀州中心局1_ATN950B_CSG", "冀州彭村基站_CSG", "冀州吉爽暖气(艺科)基站_CSG", "冀州中心局基站_CSG", "冀州县局_CX600-X8_ASG_2", "冀州碧水康庭基站_CSG", "冀州县局_CX600-X8_ASG_2" }; // 获取ASG的索引 int a1Index = -1; int a2Index = -1; for (int i = 0; i < nodesA.length; i++) { if (nodesA[i].contains("ASG_1")) { a1Index = i; } if (nodesA[i].contains("ASG_2")) { a2Index = i; } } // 添加脱管节点 // List<String> nodesUn = Arrays.asList("冀州大常庄基站_CSG", "冀州周村_CSG","冀州吉爽暖气(艺科)基站_CSG", "冀州中心局基站_CSG"); List<String> nodesUn = Arrays.asList("冀州中心局1_ATN950B_CSG"); // 根据节点数组、节点目标关系数组、asg1的索引位置、asg2的索引位置、脱管的节点名称列表构造图关系实例 GrfAllEdge grf = new GrfAllEdge(nodesA.length, nodesA, nodesZ, a1Index, a2Index, nodesUn); // 打印节点关系矩阵图 grf.printMatrix(); // 获取受影响的节点列表 List<String> list = grf.unreachableNodeAll(); System.out.println("脱管节点列表:" + nodesUn); System.out.println("受影响的节点列表:" + list); } }效果展示
下面红色小圈标志的是脱管节点,黄色节点是另外受到影响的节点。
-
通过kettle实现文件到数据库转换的ETL流程实践
kettle介绍
Pentaho Data Integration又称kettle,提供数据抽取、转换、加载的功能,纯java编写,有开源版本,纯绿色安装。 本文使用的是PDI7.1社区版本试验。pdi介绍请参见一篇博文。 版本自带详细的教程和案例,如果英文水平不错的话可以直接看原文,或者到网上一些中文社区中找资料学习。版本依赖于jdk1.8。
社区版与商业版区别
PDI包含spoon、pan、kitchen、carte四部份,spoon通过图形接口,用于编辑作业和转换的桌面应用;Pan是一个独立的命令行程序,用于执行由Spoon编辑的转换和作业;Kitchen是一个独立的命令行程序,用于执行由Spoon编辑的作业;Carte是一个轻量级的Web容器,用于建立专用、远程的ETL Server。
商业版本多的是管理调度、监控、协作开发、权限控制、集群管理等功能。
核心概念
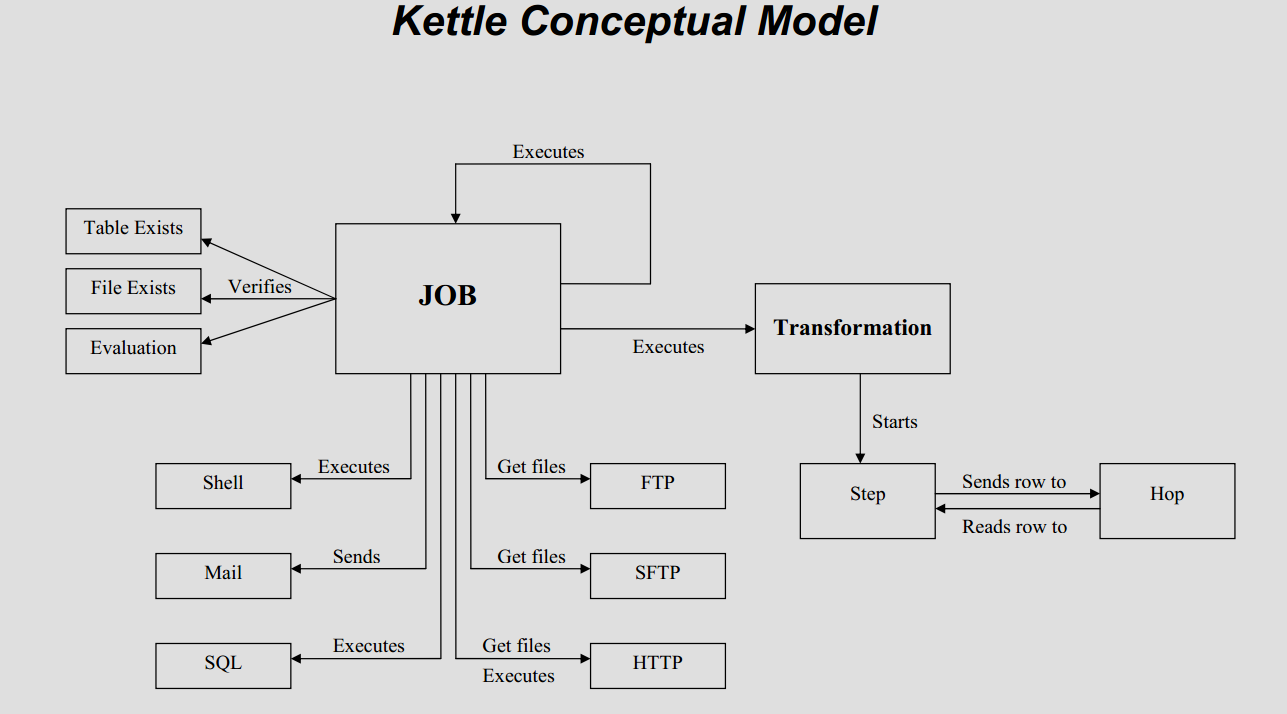 Steps(步骤)是转换的建筑模块,比如一个文本文件输入或者一个表输出就是一个步骤。在PDI中有140多个步骤,它们按不同功能进行分类,比如输入类、输出类、脚本类等。每个步骤用于完成某种特定的功能,通过配置一系列的步骤就可以完成你所需要完成的任务。Jobs(工作)是基于工作流模型的,协调数据源、执行过程和相关依赖性的ETL活动。
Steps(步骤)是转换的建筑模块,比如一个文本文件输入或者一个表输出就是一个步骤。在PDI中有140多个步骤,它们按不同功能进行分类,比如输入类、输出类、脚本类等。每个步骤用于完成某种特定的功能,通过配置一系列的步骤就可以完成你所需要完成的任务。Jobs(工作)是基于工作流模型的,协调数据源、执行过程和相关依赖性的ETL活动。入门实例
官网有一个入门案例,简书上有中文翻译。PDI7.1入门实例。
资源库使用与监控
有两种方式,一种是xml配置文件,一种是使用数据库。配置与运行完全分开,通过spoon可以将任务执行在单节点,或是集群上面。默认情况下运行节点不需要连接资源库,运行的任务都是由spoon推送给运行节点执行。没有统一的日志监控,每个节点会记录日志,如果在集群模式下需要统一执行。
carte使用
直接使用kitchen后台执行作业,作业里设置好调度策略。此种方式对于很多作业来说,不方便管理。在实际使用时,使用carte集群可以实现作业分节点运行,前提是针对流程内的环节进行集群设置。
常见使用方式
将作业和转换编排好,在linux上通过crontab进行作业调度,通过后台的日志查看运行是否正常。
优缺点分析
缺少统一的通过web浏览器的方式进行作业管理与监控,缺少任务自动切割的功能,虽然也能配置某个环节使用集群,但实际上处于单点故障的风险之中。不能作为企业级数据集成平台,缺少统一管理作业、转换的功能,也不方便进行集中的监控。数据转换的功能非常强大。
-
通过Python实现Kerberos主体管理
开发环境准备
开发环境使用eclipse进行python代码开发,安装pydev,由于eclipse版本较低,需要选择合适的pydev版本。版本安装后配置python路径,本机使用python2.7。本机python模块安装通过pip在线安装。安装flask-restful时提示要升级pip,先升级下pip。
sudo pip install flask sudo pip install --upgrade pip sudo pip install flask-restful通过菜鸟网站进行python知识简单学习。
运行环境准备
由于主要运维的环境都是linux主机,而且不能连公网,需要先在主机上通过非root用户配置一套python环境,使用版本为2.7.5。本文python模块全部使用下载包离线安装。 配置python环境请参考https://blog.csdn.net/Dream_angel_Z/article/details/51338546 需要安装的软件主要如下:
Python-2.7.5.tgz setuptools-2.0.tar.gz pip-8.1.1.tar.gz aniso8601-3.0.2.tar.gz click-6.7.tar.gz itsdangerous-0.24.tar.gz Jinja2-2.10.tar.gz MarkupSafe-1.0.tar.gz pytz-2018.5.tar.gz six-1.11.0.tar.gz Werkzeug-0.14.1.tar.gz Flask-1.0.2.tar.gz Flask-RESTful-0.3.6.tar.gz程序设计
通过python subprocess模块与kadmin交互,实现用户的管理。通过Flask将其开放成接口。JAVA应用程序调用接口实现Kerberos票据管理。subprocess模块不需要安装,Flask需要安装。
- flask接口编程学习例子:https://www.jianshu.com/p/6ac1cab17929
- subprocess编程学习例子:https://blog.csdn.net/zhouyuanlinli/article/details/78617484
增加用户的代码示例
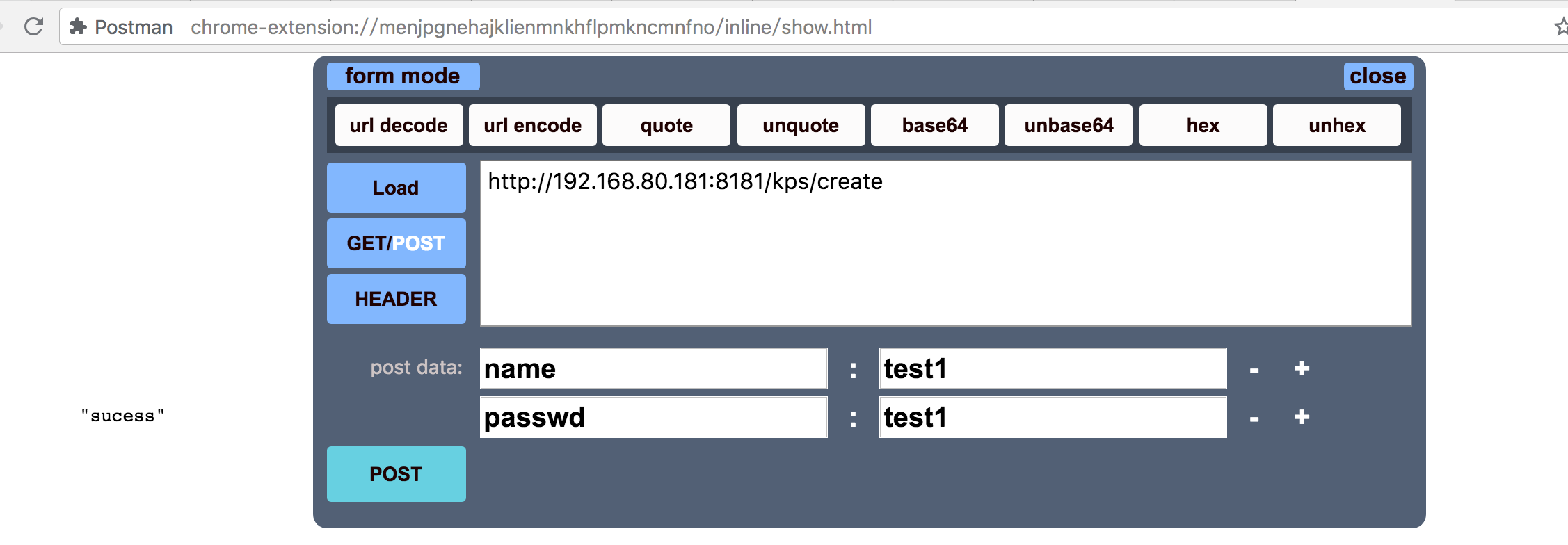
#!/usr/bin/python # -*- coding: UTF-8 -*- import subprocess from flask import Flask from flask_restful import reqparse, abort, Api, Resource app = Flask(__name__) api = Api(app) parser = reqparse.RequestParser() parser.add_argument('name') parser.add_argument('passwd') class kpm(Resource): def post(self): args = parser.parse_args() name = args['name'] passwd = args['passwd'] RunCmd.user_add(name, passwd) return "sucess", 201 api.add_resource(kpm, '/kps/create') class RunCmd(object): def __init__(self): self.cmd = 'ls' @staticmethod def local_run(cmd): print('start executing...') print('cmd is -------> %s' % str(cmd)) s = subprocess.Popen(str(cmd), shell=True, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) out, err = s.communicate() print("outinfo is -------> %s" % out) print("errinfo is -------> %s" % err) print('finish executing...') print('result:------> %s' % s.returncode) return s.returncode @staticmethod def user_add(username,passwd): cmd = r""" expect -c " set timeout 1; spawn kadmin ; expect COM { { send \"cloudera-scm-eip\r\" } } ; expect * { { send \"addprinc -pw {password} {principal}@HADOOP.COM\r\" } } ; expect *\r expect \r expect eof " """.format(principal=username,password=passwd) RunCmd.local_run(cmd) if __name__ == '__main__': app.run(host='0.0.0.0', port = 8181, debug=True)接口测试
通过http客户端发送post请求,成功创建kerberos用户。