场景说明
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。 一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。 Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。 Filebeat隶属于Beats。目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
本文所试验的场景如下,其中日志收集采用Filebeat:

环境准备
提前准备kafka环境,下载es、kibana、logstash、filebeat等软件,版本号为5.6.10,使用可以直接运行包解压即可运行。
本文为简化起见,只在单机上安装,通过elk用户安装,预先安装Jdk8。

Filebeat配置启动
提前准备kafka主题messages,配置读取/var/log/messags数据到kafka主题。
解压Filebeat介质,进入软件目录,修改配置vim filebeat.yml

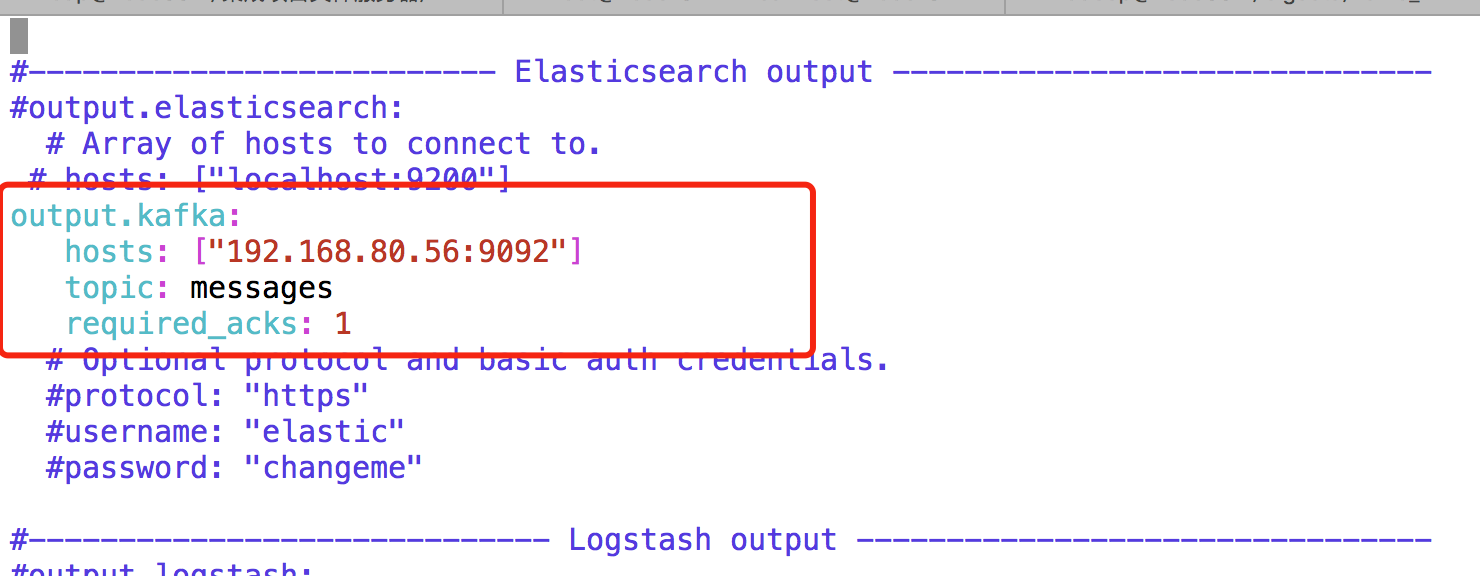 输入命令,nohup ./filebeat -e -c filebeat.yml>/dev/null 2>/dev/null & ,启动fliebeat
Kafka主题中会接收到对应消息。
输入命令,nohup ./filebeat -e -c filebeat.yml>/dev/null 2>/dev/null & ,启动fliebeat
Kafka主题中会接收到对应消息。
Logstash与ES配置启动,将kafka消息采集到ES中
解压ES软件,修改config/elasticsearch.yml配置文件,具体配置如下。
cluster.name : es_cluster
node.name : node0
path.data: /home/elk/es/data
path.logs: /home/elk/es/logs
network.host : node68
http.port : 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
直接启动可能会报错,需要通过root用户修改max file和max_map_count。 [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
启动ES,通过浏览器访问,说明启动正常。
[elk@node68 elasticsearch-5.6.10]$ bin/elasticsearch -d
[elk@node68 elasticsearch-5.6.10]$ ps -ef |grep elas
elk 14511 1 99 10:56 pts/0 00:00:13 /home/elk/jdk8/bin/java -Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -Djdk.io.permissionsUseCanonicalPath=true -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Dlog4j.skipJansi=true -XX:+HeapDumpOnOutOfMemoryError -Des.path.home=/home/elk/elasticsearch-5.6.10 -cp /home/elk/elasticsearch-5.6.10/lib/* org.elasticsearch.bootstrap.Elasticsearch -d
 解压Logstash,新建kafka2es.yml配置文件,将kafka主题消息采集到ES中。配置文件内容如下
解压Logstash,新建kafka2es.yml配置文件,将kafka主题消息采集到ES中。配置文件内容如下
input{
kafka {
bootstrap_servers => "192.168.80.56:9092"
topics => ["messages"]
group_id => "consumer-zwang"
auto_offset_reset => "earliest"
}
}
output {
elasticsearch {
hosts => "node68:9200"
codec => json
}
}
在安装目录下输入命令,启动logstash。
[elk@node68 logstash-5.6.10]$ bin/logstash -f kafka2es.yml --config.reload.automatic &
[1] 19501
启动Kibana,实现展示ES数据
解压kibana,进入安装目录,修改config/kibana.yml文件,配置ES地址和本机地址。
 输入命令启动Kibana
输入命令启动Kibana
[elk@node68 kibana-5.6.10-linux-x86_64]$ bin/kibana &
[2] 19662
打开浏览器,输入Kibana地址,默认端口是5601,可以搜索到messages日志信息

总结
增加Kafka的目的是由于Logstash在数据量大的时候会非常消耗资源,通过Kafka可以实现数据缓冲的作用。另外本文中没有对日志进行过滤处理,Logstash擅长对日志进行清洗加工,以满足日志分析需求,配置文件中通过filter脚本实现数据的清洗加工。本文中的kafka、ES、Logstash原则上都是分布式集群环境,以实现高性能高可用。
Flume也是实现实时数据采集的工具,与Logstash相比,Flume侧重数据的传输可靠性,Logstash则更轻量级,易于与其他组件配合使用,场景广泛。
Logstash支持数据输出到Hadoop环境,支持通过Socket端口收集数据,支持数据写入Redis等场,对MySQL、HBase输出连接需要定制组件才能完成数据传输。
资源
- 官网地址:https://www.elastic.co/
- 中文社区:https://elasticsearch.cn/