根据笔者与某客户的聊天,就数据处理方面的技术方案总结梳理一下,主要是目前比较主流的技术方案进行了总结。由于笔者并不是专业的数据分析专家或是业务专家,以下方案仅供参考。
常见数据存储方式
生产数据结构化类型一般存储在Oracle或MySQL中,半结构化数据一般存储在文件或是NoSQL中。由于笔者没有从事过非结构化数据的技术方案,在此并不讨论非结构化数据的处理技术。在生产库后面一般都有一个历史库或叫分析库、归档库。主要是存储海量历史数据并能进行数据的统计分析及挖掘。

数据分类
下面数据的分类主要还是从客户比较熟悉的业务视角分类的,不同的场景可能区别比较大:

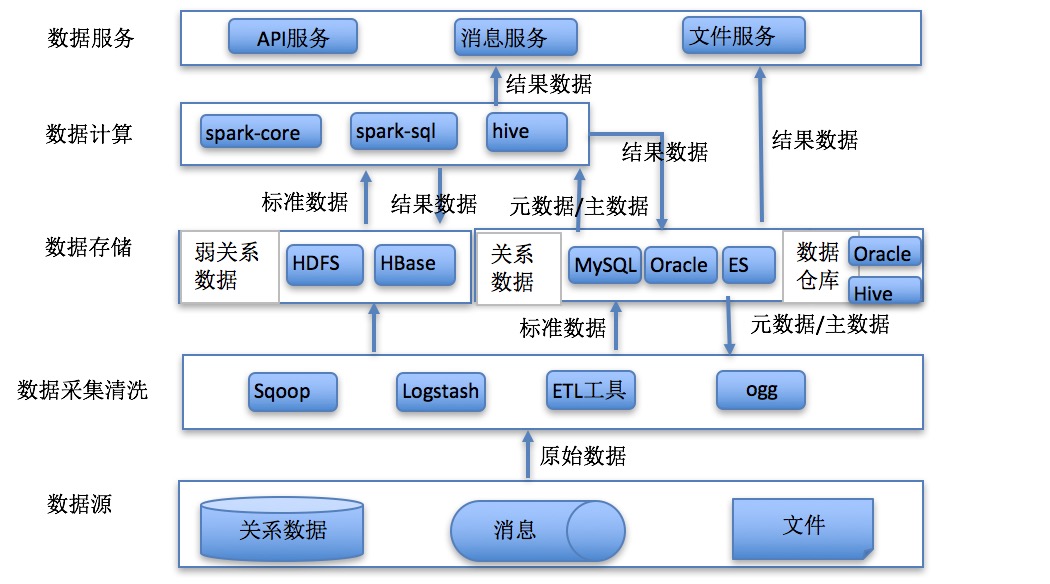
应用分类
原始数据指从数据源采集过来并没有加工的数据;标准数据指通过数据清洗转化的数据;结果数据指应用计算分析的结果:

统计分析
功能目标
通过业务规则对既有数据进行统计分析,获取目标结果的过程。
应用特点
数据来源广泛,既有实体数据、也有过程数据和配置数据,数据量大,计算量大,计算效率要求高。
方案概述
- Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要 读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的 情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系 统,简称HDFS,HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上,而且它提供高吞吐量来访 问应用程序的数据,适合那些有这超大数据集的应用程序。Hadoop的框架最核心的设计就是HDFS和 MapReduce。
- HBASE是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文 “Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System) 所提供的分布式数据存储一样,HBASE在Hadoop之上提供了类似于Bigtable的能力。HBASE是Apache的 Hadoop项目的子项目。HBASE不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。 另一个不同的是HBASE基于列的而不是基于行的模式。
- ETL过程是数据平台建设中最重要的步骤之一。ETL 规则设计和实施工作量巨大,是构建大数据核心处理 能力系统成败的关键。对于核心处理能力系统来说,ETL 主要工作是集成、转换、汇总等处理工作,最后将处理完的数据加载相关存储设备中。
技术架构
报表展示
功能目标
基于数据仓库,快速实现各类报表。
应用特点
侧重于快速的数据展示,主要用于数据决策系统。
方案概述
FineReport是帆软软件有限公司自主研发的一款企业级 web 报表软件产品,它“专业、简捷、灵活”, 仅需简单的拖拽操作便可以设计出复杂的中国式报表、参数查询报表、填报表、驾驶舱等,轻松搭建数据 决策分析系统。
技术架构

流式处理
功能目标
通过流式获取时间窗口数据,实时进行业务处理。
应用特点
海量数据采集,实时处理。例如采集性能数据根据规则进行实时预警。
方案概述
分布式流处理是对无边界数据集进行连续不断的处理、聚合和分析的过程,与MapReduce一样是一种通用计算框架,期望延迟在毫秒或者秒级别。
- Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,Kafka是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。针对不同业务,建立不同的主题用于传递各类消息。例如中兴LTE设备、华为传输设备原始数据可以分别建立不同的主题进行原始数据的流式处理。对于结果数据也可以通过主题向应用推送,从而实现实时应用。
- Spark streaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。数据可以从诸如Kafka,Flume,Kinesis或TCP套接字等许多源中提取,并且可以使用由诸如map,reduce,join或者 window等高级函数组成的复杂算法来处理。最后,处理后的数据可以推送到文件系统、数据库、实时仪表盘中。不同应用的计算任务可以使用spark集群的多租户进行资源配额管理。
技术架构
数据检索
功能目标
通过搜索各类应用系统的日志去定位系统问题,解决故障。
应用特点
海量结构化或半结构数据,存储周期短,实时性要求高,分布式采集,集中检索。
方案概述
ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats、Logstash、Elasticsearch、Kibana等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决方案。本文将会介绍ELK常见的架构以及相关问题解决。
- Filebeat:Filebeat是一款轻量级,占用服务资源非常少的数据收集引擎,它是ELK家族的新成员,可以代替Logstash作为在应用服务器端的日志收集引擎,支持将收集到的数据输出到Kafka,Redis等队列。
- Logstash:数据收集引擎,相较于Filebeat比较重量级,但它集成了大量的插件,支持丰富的数据源收集,对收集的数据可以过滤,分析,格式化日志格式。
- Elasticsearch:分布式数据搜索引擎,基于Apache Lucene实现,可集群,提供数据的集中式存储,分析,以及强大的数据搜索和聚合功能。
- Kibana:数据的可视化平台,通过该web平台可以实时的查看 Elasticsearch 中的相关数据,并提供了丰富的图表统计功能。
技术架构

数据挖掘
功能目标
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
应用特点
主要使用海量结构化数据,对数据进行清洗,建立探索模型,使用分类、聚类、关联、回归等算法实现模型的生成。其具有一定不确定性,主要用于预测,有一定的失败概率。
方案概述
- Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python包含有非常多的算法框架来实现数据挖掘和机器学习,比如scikit-learn,scikit-learn是一个基于NumPy, SciPy, Matplotlib的开源机器学习工具包,主要涵盖分类,回归和聚类算法,例如SVM, 逻辑回归,朴素贝叶斯,随机森林,k-means等算法。PySpark 是 Spark 为 Python 开发者提供的 API。
- MLlib是Spark的机器学习(ML)库。旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化和高层的管道API。
技术架构
